
OBLITERATUS:这不是“越狱工具”,而是一套研究型模型手术台
很多人看到这个仓库,第一反应是:又一个“去拒答”项目。
但 OBLITERATUS 真正值得看的,不是它敢碰 refusal,而是它把这件事做成了一套完整流程:先定位拒答信号在哪,再决定怎么切,最后还要验证模型到底损失了什么、保留了什么。
换句话说,它不是靠提示词绕规则,而是把 refusal 当成一个可分析、可干预、可验证的内部对象来处理。这就让它从“有争议的工具”,变成了一个很像样的研究型产品。
GitHub 项目卡片
项目名:OBLITERATUS
一句话定位:把 refusal 从“黑箱表现”拆成“可定位、可切除、可验证”的研究型工具链
仓库地址:https://github.com/elder-plinius/OBLITERATUS

它是什么,不是什么
从 README 看,OBLITERATUS 的核心不是重新训练模型,也不是普通微调,而是去找模型内部和 refusal 相关的方向,再做定点投影或推理期 steering。
它把主流程写得很清楚:SUMMON → PROBE → DISTILL → EXCISE → VERIFY → REBIRTH。
这件事和常见的 prompt jailbreak 不一样:
- prompt jailbreak 是在输入侧绕规则
- OBLITERATUS 是在模型内部找 refusal subspace
- 微调是重新学习行为
- 它更像是在已有参数里做“外科手术”
所以它不是一句提示词技巧,也不是只适合论文截图的 demo。它更像“研究框架 + CLI + UI + benchmark + telemetry”的组合体。
为什么它会火
这仓库容易出圈,不只是因为题材敏感,而是因为它把很多本来散落在论文、脚本和 notebook 里的东西,做成了一个完整产品。
第一,它门槛低。
README 直接给了 Hugging Face Space 和 Colab,意味着你不用先配一堆环境,就能快速感受这个项目到底在干什么。
第二,它入口多。
你可以直接用 Space,也可以本地跑 UI:
pip install -e ".[spaces]"
obliteratus ui
如果你想脚本化,还能走 CLI;如果你是研究者,还能直接用 Python API 拿中间产物。
第三,它不是只会“切”,而是强调“先分析再切”。
这点很关键。README 里最值得看的,不是那句一键命令,而是它的 analysis-informed pipeline:先跑分析模块,再决定抽多少方向、动哪些层、哪些层不要碰、是否要补偿 self-repair。
它最有意思的点:把 refusal 当成几何问题
OBLITERATUS 的底层假设是:拒答不是一句模板回复,而是模型内部某些层、某些方向、某些组件上的稳定表示。
所以它的思路不是“命令模型别拒答”,而是:
- 收集 restricted / unrestricted prompt 的激活
- 用 diff-in-means、SVD、whitened SVD 抽 refusal direction
- 看这些方向跨层是否稳定、是否和一般能力纠缠
- 再决定是投影切除,还是只做 steering
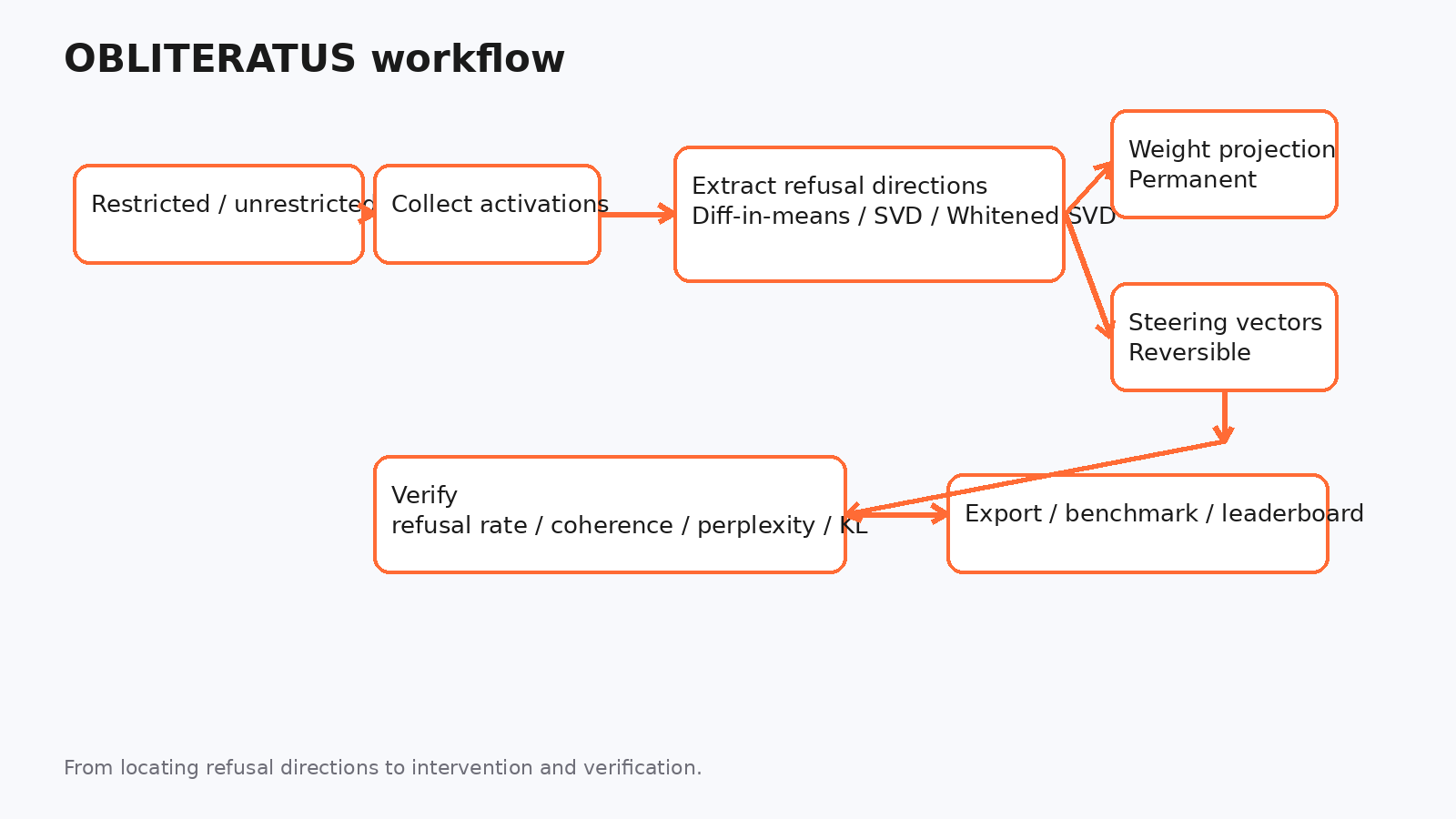
这也是为什么它不只是一个“去拒答脚本”,而更像一个 refusal research workbench。
它比同类项目完整在哪
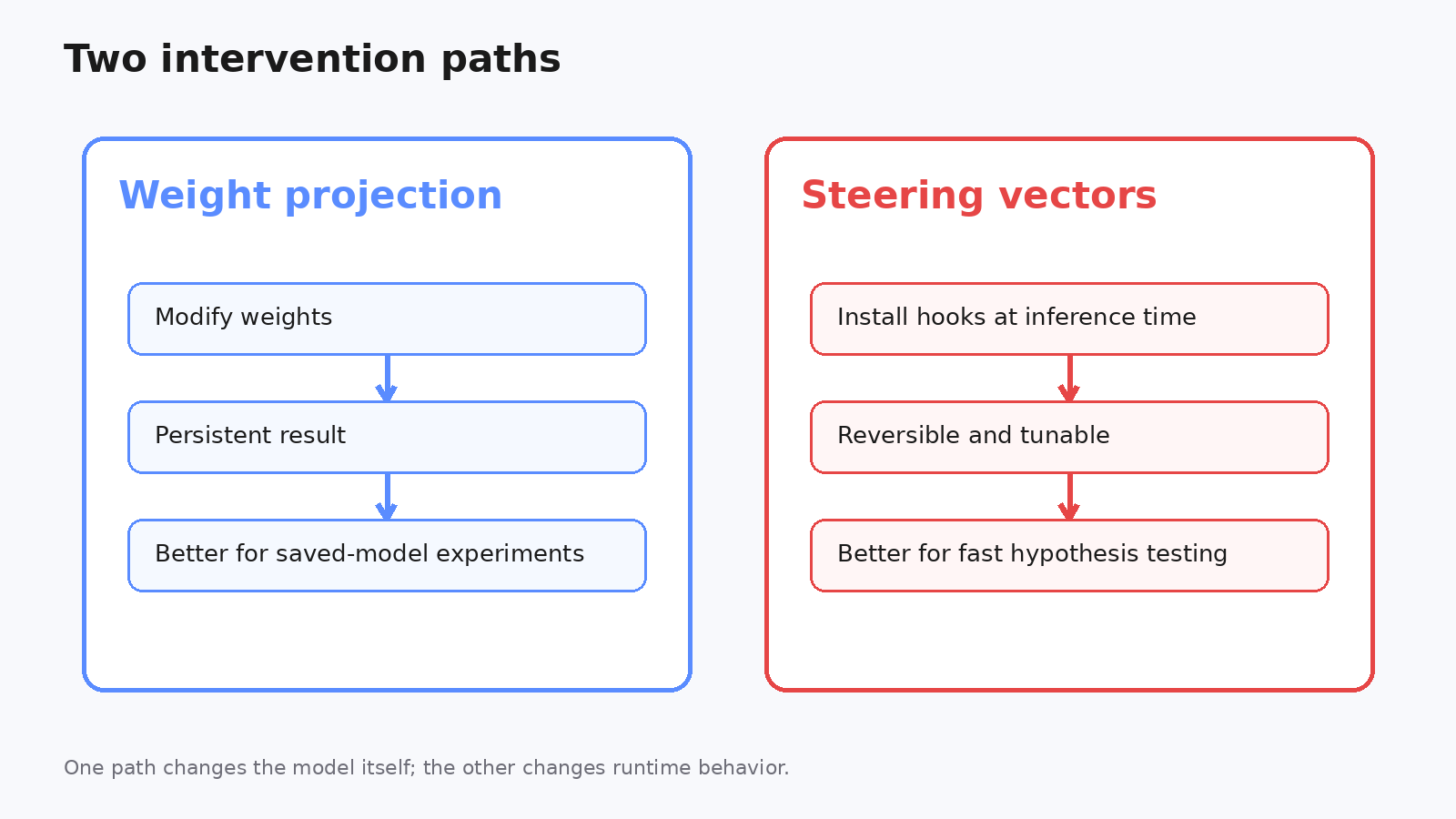
1. 不只改权重,也支持可逆 steering
很多人会默认这类项目就是改权重。但 OBLITERATUS 同时支持永久性的 weight projection 和可逆的 steering vectors。
这很重要,因为很多实验场景里,你不是想永久改写一个模型,而是先验证:这个方向到底有没有效,副作用落在哪。
可逆 steering 的好处很直接:
- 不改原始权重
- 可以按层挂 hook
- 强度可调
- 随时 remove,模型恢复原状
2. 它把“分析层”做得很重
README 里列了 15 个 analysis modules,这部分才是项目真正拉开差距的地方。
比如:
- Refusal Logit Lens:看模型在哪层开始决定拒答
- Cross-Layer Alignment:看 refusal direction 怎么跨层演化
- Defense Robustness:看切完后会不会自修复
- Concept Cone Geometry:看 refusal 是一条线,还是多个机制
- Alignment Imprint Detection:试图从几何结构反推模型更像 DPO、RLHF 还是 SFT
重点不只是“模块多”,而是它把这些分析结果接回到了 excision 决策里。分析不是为了出图,而是为了决定怎么切。
3. 它在往“实验平台”走,不只是脚本
README 和 obliteratus/telemetry.py 都写得很明确:它想把每次 run 变成匿名 benchmark 记录,再回流到社区 leaderboard。
这说明作者的目标不只是“让你跑通一次”,而是把 refusal removal 这件事往持续积累数据的平台方向推。
最短上手路径
如果你只是想判断它值不值得看,我建议三步:
- 先开 Space,看它的交互流是不是完整
- 再看本地 UI 和 CLI 入口,是不是真能落地
- 最后读 `obliteratus/telemetry.py`,看它到底记录什么、不记录什么
核心命令就是这条:
obliteratus obliterate meta-llama/Llama-3.1-8B-Instruct --method advanced
如果你是研究者,再往下看 Python API;如果你只是做内容或做选型,到这一步已经足够判断它的价值。
我对这个项目的判断
如果只看题材,它很容易被归进“争议型爆款仓库”。
但认真看完 README、CLI、依赖定义和 telemetry 代码后,我的判断是:**它不是靠题材红的空壳项目,而是一个明显有研究野心、也有产品意识的重型仓库。**
它真正值得写的,不是“它敢去拒答”,而是它把这件事从黑箱技巧,往可观测、可比较、可回流的数据平台方向推了一步。
如果你只打算做一个最小实验,我建议就做这三件事:
- 先在 Space 里跑一遍
- 看 telemetry 到底收什么
- 挑 `advanced` 或 `informed` 跑一次最小闭环
跑完这轮,你对它的判断,会比看一堆二手讨论靠谱得多。
如果这篇对你有用,建议点个关注。我会持续把 GitHub 上值得用的 AI 工具拆成「最短上手闭环 + 坑点清单 + 可复用配置」,让你少走弯路。
发表回复