Supermemory:它想抢的,其实是 AI 的上下文层入口
- 对比与选型
- 8天前
- 18热度
- 0评论
supermemoryai/supermemory 最值得看的,不是“给 AI 加记忆”这个口号, 而是它在试图把 memory、RAG、user profile、connector 这些原本分散的能力,压成一个统一入口。
换句话说,它卖的不是单点功能,而是一层更完整的 AI context stack。
仓库地址先放前面:https://github.com/supermemoryai/supermemory
项目卡片
- 项目名:Supermemory
- GitHub:https://github.com/supermemoryai/supermemory
- 增长信号:仓库主打自己在 LongMemEval、LoCoMo、ConvoMem 三个主流 memory benchmark 上拿到第一,最近 30 天也还在持续迭代
- 一句话判断:它真正想卖的不是 memory,而是把 memory、RAG 和 profile 一起包掉的那层基础设施。

图注:README 首页就把它定义成 memory and context layer for AI,不是单点记忆插件,而是一层更完整的上下文基础设施。
先别急着看 benchmark,先看它有没有把问题讲清楚
这类项目最容易写空的地方,就是一上来就说自己能“长期记忆”“个性化”“上下文增强”。
Supermemory 至少有一个地方是清醒的:它没有把 Memory 和 RAG 混成一句空话。
它明确区分了两件事:
- RAG:检索文档块,偏知识库、偏文档
- Memory:跟踪关于用户的事实,会处理时间变化、矛盾信息和过期内容
README 里甚至直接写了:
Memory is not RAG.
这句话很关键。
因为很多所谓“记忆系统”,本质上只是把用户说过的话也当文档切块,再拿去检索。这样当然能“搜到”,但它并不真的理解“我之前住在纽约,现在搬到旧金山”这种会变化的事实关系。
Supermemory 真正想补的,是这层能力:记住用户事实、处理新旧冲突、自动遗忘过期信息,最后把个体上下文和通用知识检索一起给模型。
它到底在卖什么?
README 开门见山写得很重:
- memory and context layer for AI
- #1 on LongMemEval / LoCoMo / ConvoMem
- full RAG, connectors, file processing — the entire context stack, one system
翻成人话就是:它不是只想做“记忆插件”,而是想做 AI 应用里的上下文底座。
因为现在很多产品在做 AI 记忆时,实际上只补了一小块:有的做 conversation memory,有的做知识库检索,有的做 profile,有的做 connector,有的做文件抽取。
Supermemory 的路线更激进一点:既要记住用户,又要接知识库,还要接外部数据源,还要把这些结果在一次查询里一起返回。
这就是它跟普通 memory API 最大的区别。
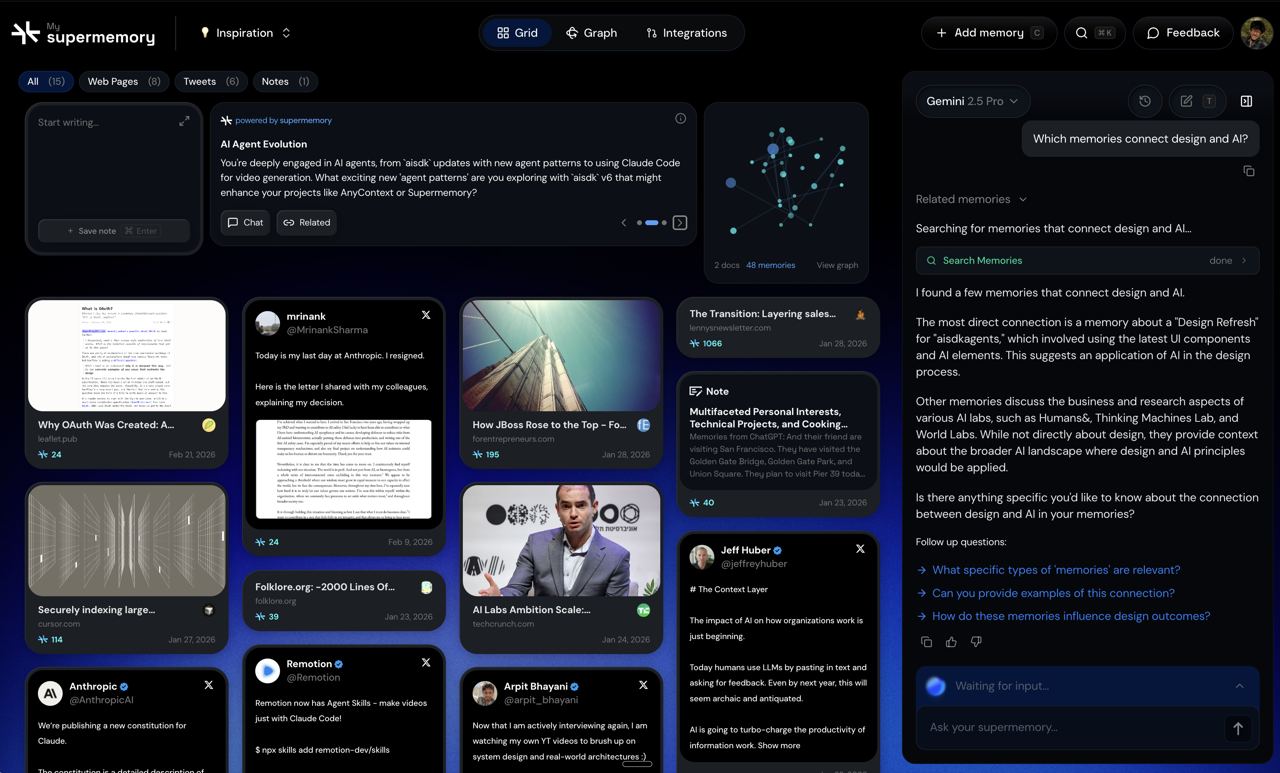
图注:从 README 的产品图也能看出来,它不只是在讲 API,而是在做一个真正面向使用场景的记忆产品层。
它的 API 设计,在往“你少配系统”这条路走
README 里的 quickstart 很直接:
这里最关键的,不是 add() 和 profile() 这两个函数本身。 而是它试图把开发者原本要自己拼的几层流程直接折叠掉:
- 不用自己先搭 embedding pipeline
- 不用先选向量库
- 不用自己设计 chunking
- 不用再额外拼一个 profile 层
- 不用自己做 memory + docs 的二次融合
这类项目我最怕的是“能力很多,但接起来很碎”。Supermemory 至少在 API 设计上,是在反着做。
它卖的不是单点能力,而是:“你少配系统,我来给你一个能直接接进应用的上下文层。”
真正拉开差距的地方,可能不是 API,而是接入位
如果你只看 README,会以为这是一个标准的 SDK + API 项目。
但我往下看了一圈,觉得它另一个更值得注意的点,其实是 tools / middleware 这一层已经铺得比较深。
仓库里不只是有 supermemory SDK,还有单独的 @supermemory/tools,而且已经拆了不同入口:
@supermemory/tools/ai-sdk@supermemory/tools/openai@supermemory/tools/mastra
最关键的是它提供了一个很顺手的包装方式:withSupermemory。
比如在 AI SDK 里,可以直接这样接:
这层设计很聪明。
因为很多“记忆系统”看起来能力很强,但真正接进业务代码时,开发者要自己处理:什么时候查记忆、什么时候把记忆注入 prompt、什么时候保存新记忆、多轮 tool call 时怎么避免重复请求。
而 withSupermemory 这种包装,实际上是在争夺一个更高价值的位置:不是当 memory backend,而是当 agent 调用链里的默认上下文层。
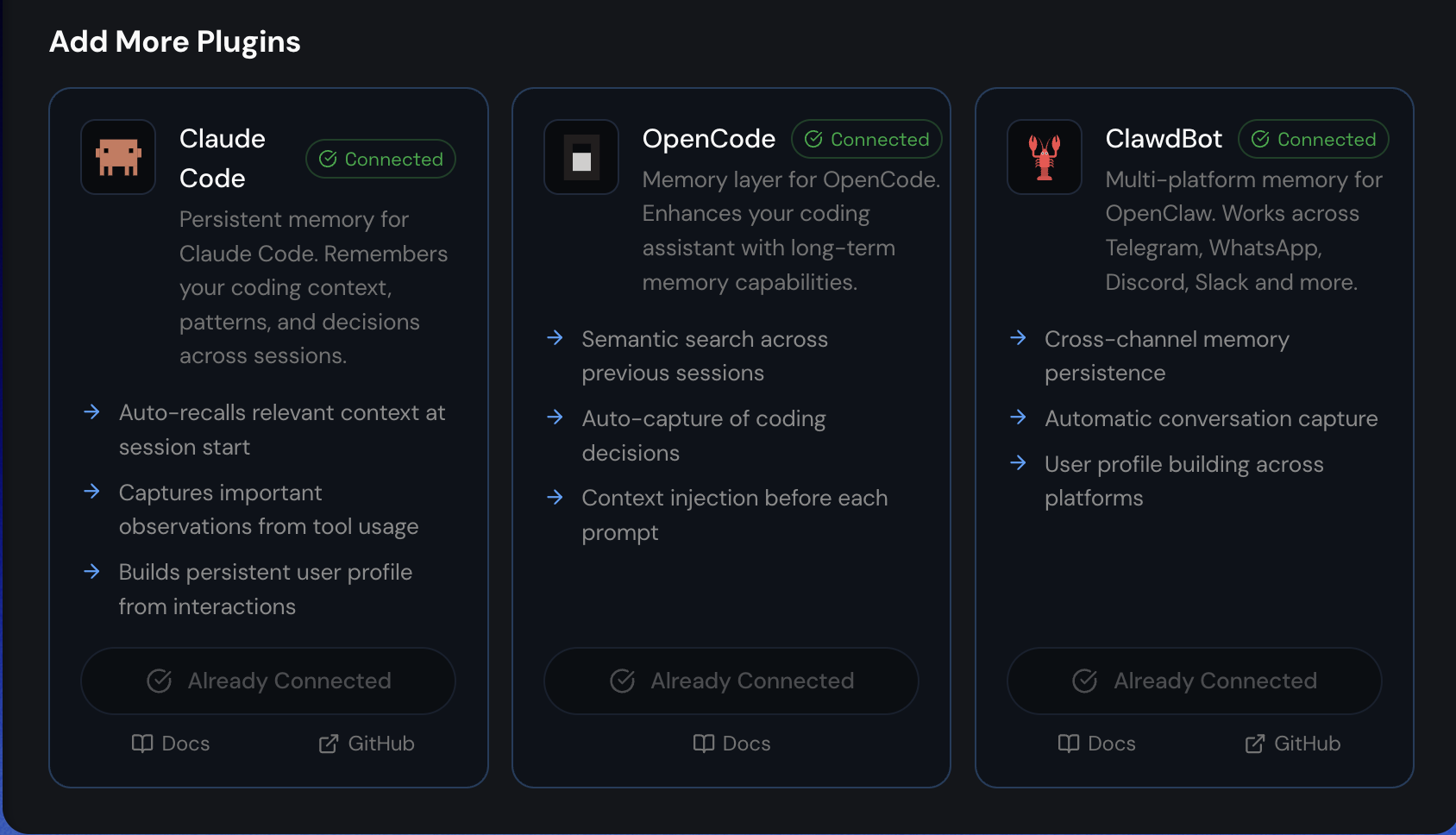
图注:README 里把插件、MCP 和接入链路放得很靠前,说明它不只想做 API,而是想占住 AI 工具的默认记忆入口。
它现在最像什么?
我会把它看成一套“上下文基础设施”。
也就是:不管上下文来自哪里——聊天、偏好、历史项目、PDF、图片、视频、Gmail、Notion、GitHub——最后都尽量进入一套统一结构,然后通过同一套查询接口返回给模型。
这个方向我觉得是成立的。因为 AI 应用现在一个很现实的问题就是:上下文来源太散了。
如果这些东西一直分开,开发者就得自己拼一个越来越复杂的 context pipeline。Supermemory 想直接把这件事产品化。
那它值不值得押注?
Supermemory 最有传播力的点,是 benchmark。LongMemEval、LoCoMo、ConvoMem 上拿第一,当然会让人愿意多看一眼。
但 benchmark 第一,不等于你的业务接进去就一定最好用。
真实产品里更难的通常是这些问题:
- 接入成本到底多低
- profile 质量稳不稳
- 冲突事实处理得够不够可靠
- connector 同步会不会脏
- 多源上下文混在一起后可控性怎么样
- 成本和延迟能不能接受
所以我现在对它的判断是:方向很对,产品野心也够大,确实值得盯;但真正值不值得长期押注,还得继续看它在真实接入链路里的稳定性和可控性。
不过如果你最近正在看 AI memory、RAG、agent context 这条线,这个仓库是绕不过去的。至少在“AI 上下文层应该长什么样”这件事上,Supermemory 已经比很多项目讲得更完整了。
如果这篇对你有用,建议点个关注。我会持续把 GitHub 上值得用的 AI 工具拆成「最短上手闭环 + 坑点清单 + 可复用配置」,让你少走弯路。
关注微信公众号
想第一时间看到后续的工具拆解与实战更新,欢迎扫码关注公众号。

- 最新评论
- 评论区