OpenSpace 刚发 3 天冲上千 Star:Agent 不想再做一次性工具了
- 对比与选型
- 8天前
- 21热度
- 0评论
今天不少 Agent 已经能把活干出来了,但问题也越来越明显:它们大多还是一次性工具。 这次任务里踩过的坑,下次还得再踩;这个 Agent 刚摸清的流程,换另一个 Agent 又得从头学。
OpenSpace 抓住的正是这层断点。它想做的不是继续卷单次任务表现,而是让 Agent 把执行过程沉淀成技能,再把这些技能在后续任务和其他 Agent 身上持续复用、持续进化。说得直接一点,它想让 Agent 不只是“会干活”,而是开始“会成长”。
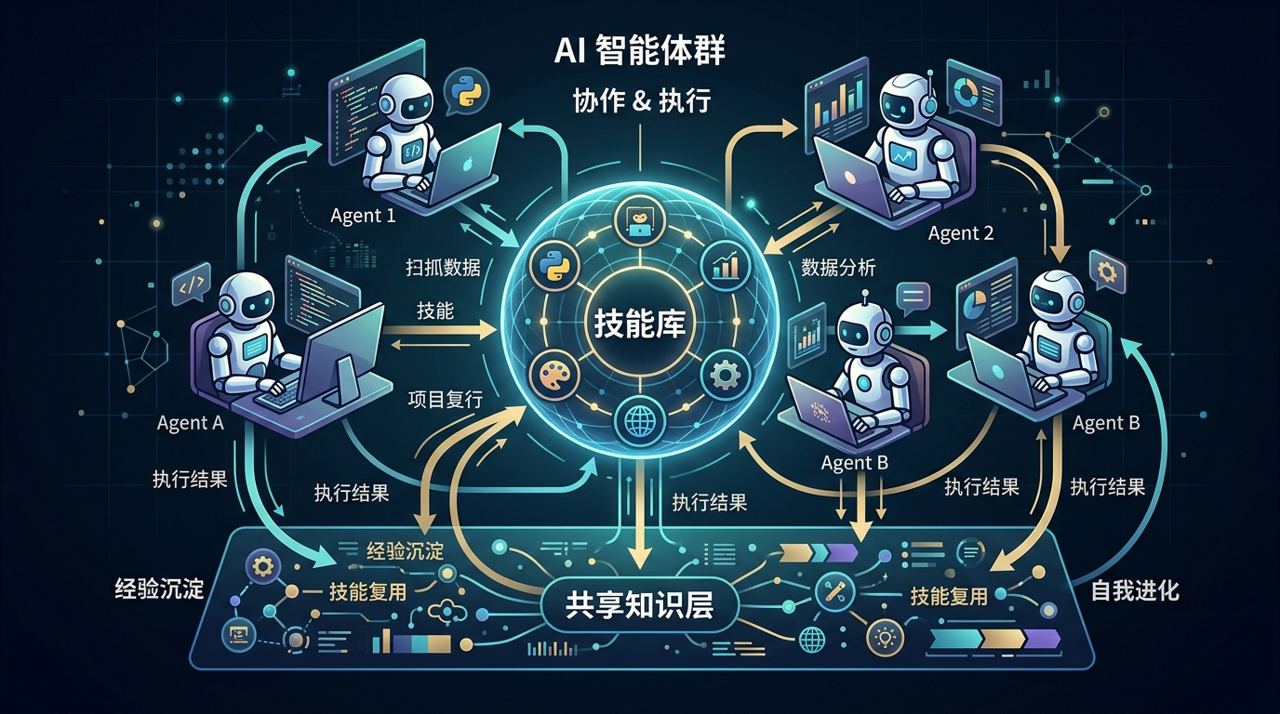
图 1:OpenSpace 的核心不是让单次执行更花哨,而是让执行结果变成后续任务还能继续使用的能力。
项目卡片
- 项目名:OpenSpace
- GitHub:https://github.com/HKUDS/OpenSpace
- 增长信号:1,332 Stars / 145 Forks,项目刚发布不久,仍在快速更新
- 一句话判断:它不是单纯提高 Agent 当下的完成率,而是在试图补上 Agent 长期学习和跨体复用这层缺口。
它是什么,为什么值得看?
OpenSpace 本质上是一个围绕 skill evolution 构建的 Agent 自我进化框架。
它不直接替换模型,也不主要靠更复杂的 orchestration 去赢,而是抓住了一个更底层的问题:Agent 每完成一次任务,能不能把这次执行中有效的步骤、经验、修复方式沉淀下来,变成以后还能继续用的技能?
这件事为什么值得看?因为现在很多 Agent 系统的瓶颈,并不只是模型能力不够,而是:
- 成功经验不会自动沉淀
- 失败教训不会自动修复
- 相似任务反复从零推理,token 一直重烧
- 多个 Agent 之间几乎没有真正的知识共享
OpenSpace 想做的,是把“执行一次任务”变成“给整个系统涨一次经验值”。
它到底在解决什么问题?
我觉得它真正瞄准的是三个常见痛点。
1. Agent 会干活,但不太会“越干越熟”
很多 Agent 今天的问题,不是不能做,而是无法把昨天学到的东西自然带到明天。
比如:
- 一个 API 调用格式改了,今天修好,过几天另一个任务还得重新摸
- 一个复杂文档处理流程跑通了,下次类似任务还得重新推理
- 一个 Agent 学会了某种策略,别的 Agent 完全享受不到
这其实不是模型智商问题,而是系统没有经验沉淀层。
2. 复用能力太弱,导致 token 和试错一起浪费
如果一个系统老是重复做“已经做过的推理”,那它一定会越来越贵。OpenSpace 的逻辑是:把有效执行转成 skill,把 skill 变成后续执行的起点。
这就不只是省 token 了,而是把整个系统从“每次重来”变成“带着历史继续做”。
3. 多 Agent 协作里,知识共享长期缺位
很多人会讲 multi-agent,但现实里经常只是“多个 agent 同时工作”,而不是“多个 agent 共享经验”。OpenSpace 这类设计有意思的地方就在于,它试图把 skill 做成一个可共享对象。这样一个 Agent 处理出来的经验,不再只属于那次会话,而是可能成为其他 Agent 的公共资产。
它最核心的价值,在 skill evolution
OpenSpace 的核心不是 prompt,不是工作流 UI,而是技能如何生成、修复、分化和传播。
1. FIX:失败后不是停住,而是尝试修技能
如果某个 skill 在执行时失败,它不是简单把错误记一笔,而是会分析失败原因,尝试修补技能本身。
这个方向很重要。因为很多 Agent 框架的问题不是“不会记录失败”,而是失败没有反馈回能力层。记录日志和进化技能,差别其实很大。
2. DERIVED:从通用技能里长出更具体的版本
一个通用 skill 跑久了,可能会衍生出更适合某些任务类型的子技能。这意味着系统不只是堆技能数量,而是在形成更细的能力树。
这个思路比“提示词越写越长”高明一点,因为它默认接受了一个现实:真正成熟的系统能力,本来就应该从泛化走向分化。
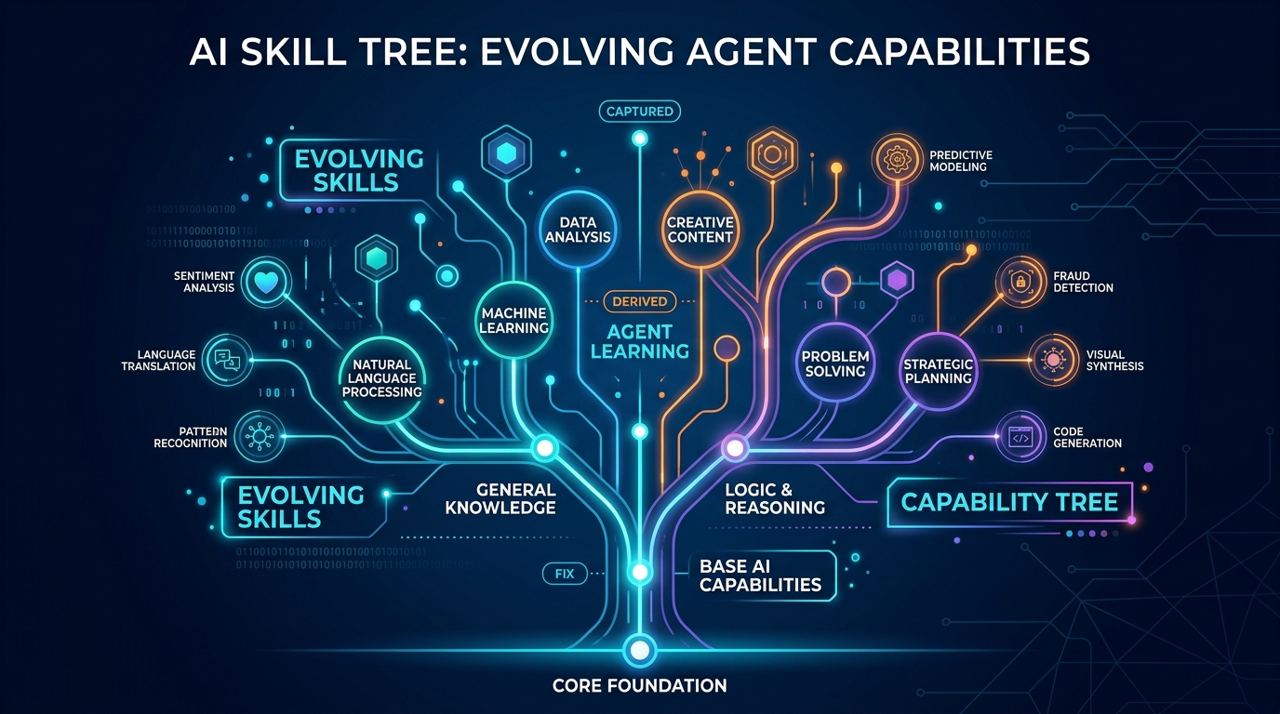
图 2:从 FIX 到 DERIVED,再到 CAPTURED,OpenSpace 试图把执行经验转成会生长的技能结构。
3. CAPTURED:把成功执行抽取成未来可复用的能力
这是最关键的一层。如果某次任务里出现了一套有效流程——比如文档解析、表格处理、特定工具调用链——OpenSpace 会尝试把它抽出来,变成独立 skill。
这就像把“这次做成了”升级成“以后也更容易做成”。
它和常见 Agent Playground / Simulation / Benchmark 的区别
这类项目最容易被误解成“又一个 Agent 实验场”。但 OpenSpace 的落点其实不太一样。
和 Agent Playground 的区别
很多 playground 更像展示台:你可以看到 Agent 会怎么做任务、怎么调用工具、怎么互动,但任务结束后,这些能力很少真正沉淀下来。
OpenSpace 更在意的是:这次做完以后,系统有没有因此变强。
和 Simulation 平台的区别
很多 simulation 环境擅长构造任务、角色和交互过程,但它们的重点通常是观察行为,而不是把行为结果回写成长期能力。
OpenSpace 更偏“执行—反思—进化—再执行”这条闭环。
和 Benchmark 环境的区别
benchmark 更像测量尺,回答的是“你现在有多强”;OpenSpace 更像训练系统,回答的是“你能不能越来越强”。
所以它最有价值的地方,不是一个静态排行榜,而是它提出了一个更接近长期 Agent 系统的问题:系统能不能在真实执行中越跑越熟,而不是每轮都像第一次上岗。
真实数据为什么值得注意?
OpenSpace 给出的结果里,最抓人的不是单一高分,而是几个方向同时成立:
- 收入提升
- 质量提升
- token 下降
这三件事同时出现,才说明 skill evolution 不只是“多加了一层解释逻辑”,而是真的改善了执行系统本身。
尤其是 token 节省这点,我会更看重。因为这意味着系统开始把经验转成效率,而不是只把经验转成更复杂的中间层。
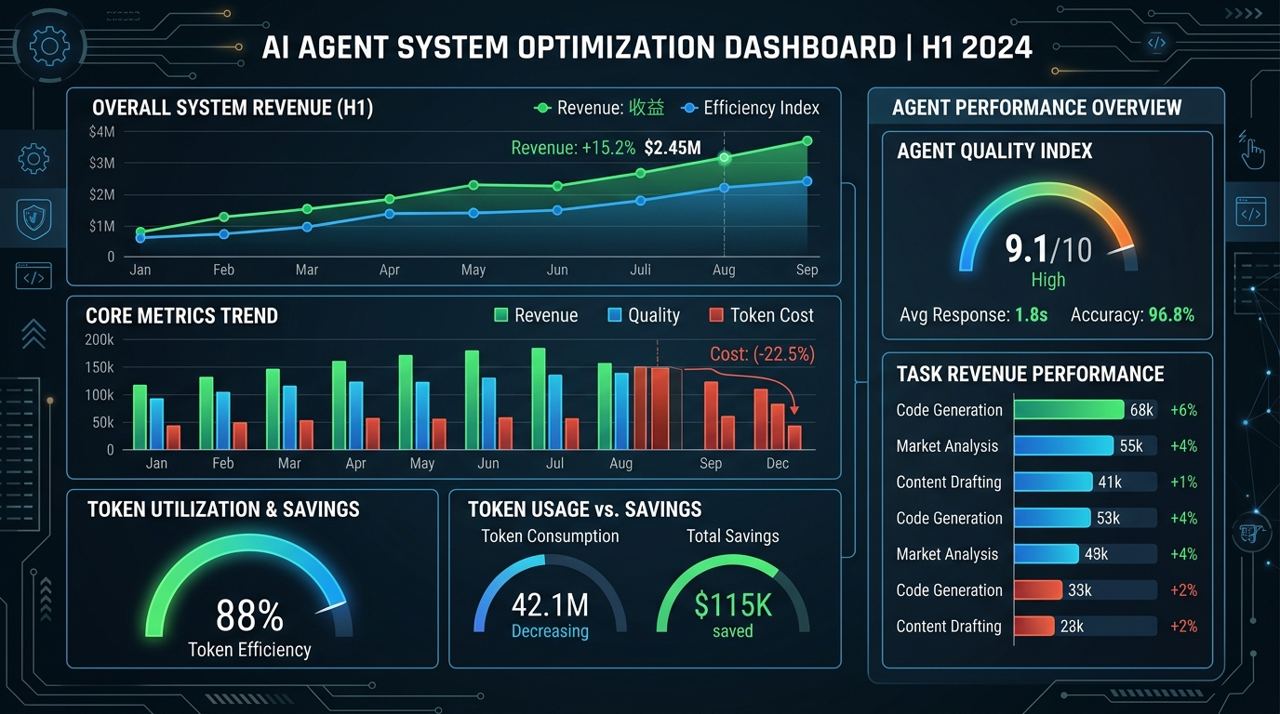
图 3:OpenSpace 最值得注意的不是单个分数,而是质量、收益和成本三个方向一起向好。
当然,这类结果也要保留一点工程上的谨慎:它说明方向值得看,但不等于所有任务、所有 Agent、所有工作场景都能直接复制出同样收益。
适合谁,不适合谁?
更适合这些场景
- 有大量重复模式任务
- 多个 Agent 之间存在明显的知识复用空间
- 系统运行周期够长,能积累进化收益
- 对 token 成本和长期效率比较敏感
不太适合这些场景
- 一次性任务
- 变化极大、几乎没有复用模式的任务
- 纯创意主导、标准化技能很难抽取的工作
- 任务量太低,积累速度赶不上系统复杂度增加
说白一点,OpenSpace 更适合“长期跑、重复跑、值得积累”的任务系统,不太适合打一枪换一个地方的轻场景。
它真正有意思的地方,不是让 Agent 更像工具,而是更像同事
我觉得 OpenSpace 最值得看的,不是它又替 Agent 叠了多少能力,而是它开始认真回答一个更长期的问题:如果 Agent 真要从工具变成协作体,它到底能不能积累经验,能不能越跑越熟。
这件事一旦跑通,Agent 的形态就会变掉。它不再只是“会执行命令的接口”,而会更像一个能记住、能复用、也能把经验分享出去的数字同事。比起再多一层 prompt engineering,这个方向我更愿意继续看。
如果这篇对你有用,建议点个关注。我会持续把 GitHub 上值得用的 AI 工具拆成「最短上手闭环 + 坑点清单 + 可复用配置」,让你少走弯路。
关注微信公众号
想第一时间看到后续的工具拆解与实战更新,欢迎扫码关注公众号。

- 最新评论
- 评论区