Claude Code 开始带团队了:12.6k Star 的 OMC,正在把多智能体编排做成工程现实
- 对比与选型
- 8天前
- 30热度
- 0评论
如果你已经在用 Claude Code,看到 oh-my-claudecode(OMC)时,大概率会先冒出一个问题:它到底只是套了一层工作流,还是在认真解决复杂任务里的协作问题?
我一开始也偏向前一种判断。但往下看之后,这个项目真正让我改观的,不是它又加了多少命令,而是它试图把“规划、执行、验证、修复”这几件原本需要人来盯的事,组织成一条可复用的多智能体流水线。它想做的,不是让 Claude Code 更像一个更会聊天的助手,而是让它更像一支能分工、能返工、也能积累经验的小团队。

图 1:用“团队协作”而不是“单 agent 对话”来组织复杂工程任务,是 OMC 最核心的产品判断。
项目卡片
- 项目名:oh-my-claudecode
- GitHub:https://github.com/Yeachan-Heo/oh-my-claudecode
- 增长信号:12,682 Stars / 839 Forks,最近仍在持续活跃更新
- 一句话判断:它让 Claude Code 从“你得学会怎么驾驭它”,变成“它先替你组织一支 AI 团队”。
它到底是什么,为什么值得看?
如果只用一句话概括,OMC 是一套围绕 Claude Code 构建的 teams-first 多智能体编排系统。
它不是简单地给 Claude Code 包一层命令别名,也不是做几个 prompt 模板集合。它真正做的是把复杂工程任务拆成一条可复用的流水线:有人负责规划,有人负责补需求规格,有人执行,有人验证,有人修复,最后再循环到通过为止。
这件事为什么值得看?因为它击中的不是模型能力本身,而是复杂开发任务里的协作问题:
- 单个模型容易在长链路任务里失焦
- 用户自己拆任务的成本很高
- 每次踩过的坑很难沉淀成后续可复用经验
- 复杂任务常常不是“写出来”就完了,还要验证、返修、再验证
换句话说,OMC 不是在提升 Claude Code 的“单次回答质量”,而是在提升一个 AI 工程流程的组织能力。
它解决的核心问题,不是写代码,而是“怎么协作”
Claude Code 单独用当然能干活,但你会很快撞上几个现实问题。
1)复杂任务需要的不是更长 prompt,而是角色分工
比如你让它“给现有项目加一个 REST API,再补测试,再做文档,再跑一遍验证”,这其实不是一个原子任务,而是一串不同类型的子问题:
- 先理解现有代码结构
- 再定义接口和边界
- 然后编码
- 然后验证
- 最后修错
如果全靠一个 agent 顺着做,它并不是做不到,而是容易在不同抽象层之间来回切换,最后把计划、执行、验证搅成一锅。OMC 的思路就是:别再让一个 agent 同时扮演所有角色。
2)经验复用不能只靠“下次记住”
很多 AI 编程体验差,不是因为第一次做不好,而是因为第二次遇到类似问题,还要从头再教一次。这类“不会积累”的体验,在长期工程里很伤。
OMC 的一个关键点,是它会把解决过的问题抽成 skill,沉淀到项目级或用户级的技能目录里。下次再遇到相近问题,不是重新聊天,而是自动调用已有经验。
3)真正难的不是生成,而是收尾
很多工具都擅长“先给你生成一个看起来差不多的版本”,但工程里最麻烦的部分往往是后面那段:
- 跑测试
- 看报错
- 修问题
- 再验证
- 直到真的过
OMC 的价值之一,就是把这段“人类最容易疲劳、最容易半路接管”的环节体系化了。
teams-first / multi-agent orchestration,具体体现在哪?
OMC 最核心的设计,不是 agent 数量多,而是它把协作流程做成了阶段化流水线。
一个典型 Team 流程大概像这样:
team-plan → team-prd → team-exec → team-verify → team-fix
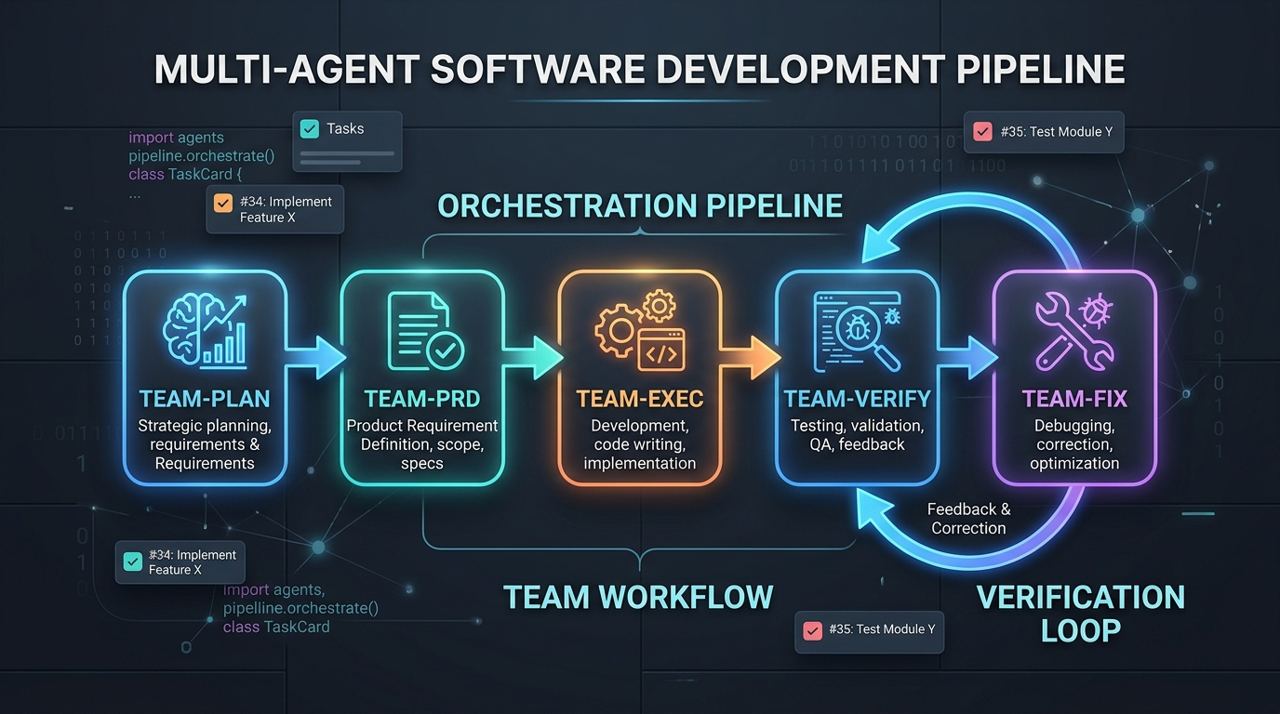
图 2:OMC 的关键不是“多开几个 agent”,而是把 plan、prd、exec、verify、fix 串成可循环的工程流水线。
这个顺序很重要,因为它不是“并行起几个 Claude Code 窗口”那么粗糙,而是明确区分了:
- plan:先拆清楚任务
- prd:把需求补到足够可执行,避免模糊描述直接落代码
- exec:进入实现阶段
- verify:独立验证结果
- fix:发现问题后自动修复,再循环
这意味着它做的不是单 agent 加速,而是把软件开发流程本身编码进了工具里。
另外,OMC 内置了大量按职责划分的专业 agent。它背后的意思不是“32 个 agent 听起来很酷”,而是它默认接受一个事实:架构分析、功能实现、验证修复、研究探索,本来就不该是同一个工作模式。
再往下一层,它还做了模型路由。简单任务用更轻的模型,复杂推理留给更强的模型。这不是噱头,而是一个很现实的工程优化:当你真的开始让多 agent 参与任务时,token 成本和执行效率立刻就变成系统设计问题了。
它和直接用 Claude Code,到底差在哪?
Claude Code 更像一个很强的个人执行者;OMC 更像一个会先组织再动手的小型 AI 开发团队。
区别主要在四层。
第一层:从“串行对话”变成“流程驱动”
直接用 Claude Code,你通常是这种节奏:先提需求,它给方案;你补约束,它再改;你提醒它测试,它再补;最后你还得自己判断有没有漏项。
而 OMC 的 Team 模式更像:你给目标,它自己先拆、再写、再验、再修。你不是每一步都要盯着。
第二层:从“会做一次”变成“能积累经验”
OMC 的 skill 系统,是它和很多单 agent 工具最实在的分界线之一。
如果某次任务里发现了一个特定坑,比如某个框架的代理崩溃、某类测试环境配置、某种代码组织约束,OMC 可以把这类经验萃取成结构化技能。下次触发相关语义时,它就不是“想起类似经验”,而是直接加载处理规则。我一般看这类项目,也会优先判断它有没有“越用越值钱”的机制,OMC 在这里是加分的。
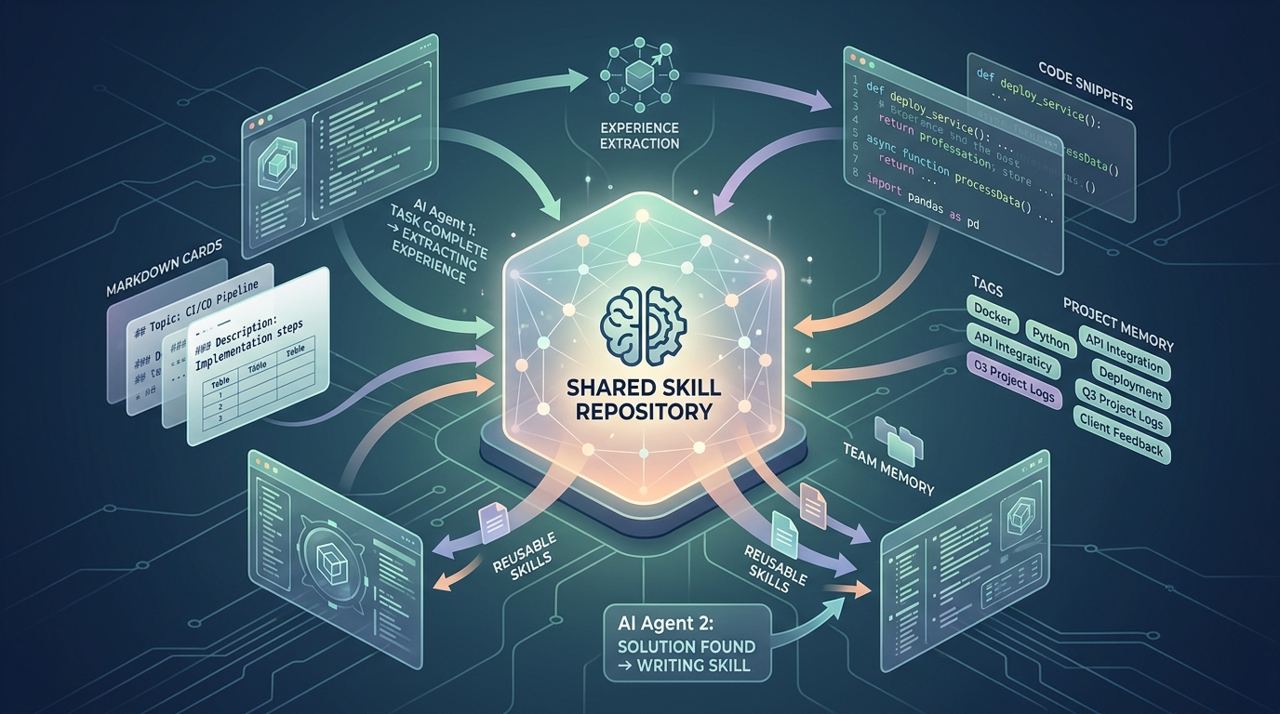
图 3:skill system 的价值不只是“会记住”,而是把一次解决方案变成团队后续可复用的处理规则。
第三层:从“能产出”变成“要交付”
很多 AI 编程工具的问题不是不会写,而是缺乏一种内建的交付完成机制。OMC 的 verify/fix 循环,实际就是把“先过验证再算完成”写进系统逻辑。
这听上去朴素,但很关键。因为只要没有这层闭环,AI 工具就很容易停留在“给你一个像样答案”的层面,而不是“帮你推进到可交付状态”。
第四层:从“你适应工具”变成“工具适应你的工作方式”
很多人不是不想用 Claude Code,而是不想额外学习一整套使用哲学、命令体系、提示词技巧,再把自己训练成调度器。OMC 的卖点就在这里:你尽量用自然语言提需求,它来把协作结构补上。
真实门槛和适用边界,也得说清楚
这类项目如果只写优点,很容易失真。OMC 值得看,但它也不是没有代价。
先说门槛
它并不是一个“装完就丝滑无脑起飞”的轻工具。你至少要接受这些前提:
- 你本来就在用 Claude Code CLI
- 你愿意把开发流程交给一层 orchestration
- Team 模式等能力对运行环境有要求,比如 tmux 等基础设施
- 如果还接入 Gemini / Codex 等混合能力,复杂度会继续上升
所以它不是给“偶尔改一行代码”的人准备的。
它最适合什么场景?
我觉得最适合三类任务:
- 中大型项目的功能开发
- 需要多阶段验证和返修的任务
- 团队希望把 AI 使用经验沉淀下来,而不是每次重新摸索
反过来,如果你只是改一个小 bug、调一段文案、修一两个文件的小逻辑,而且自己已经知道怎么 prompt Claude Code,那直接用 Claude Code 往往更快。
还有一个很现实的问题:编排复杂度会转移到底层
从社区讨论里也能看到,OMC 不是没有工程负担。比如有 issue 提到 mcp-hub 的内存占用问题,本质上反映的是:当你把多智能体协作、技能匹配、状态管理、进程调度都做进来之后,系统基础设施会迅速变重。
这类问题不是 OMC 独有,而是所有认真做 multi-agent orchestration 的项目迟早都要面对的账。它把用户侧流程简化了,但系统侧复杂度并没有消失,只是被更专业地接住了。
最后一句判断
我对这个项目的最终判断是:OMC 值得看的,不是它替 Claude Code 叠了多少功能,而是它开始认真处理一个更难、也更接近工程现实的问题——当一个 AI 不再只负责回答,而开始参与完整开发流程时,协作、验证和经验沉淀到底该怎么组织。
所以这篇文章如果只留一句结论,我会留这句:OMC 不一定适合所有人,但它确实让“多智能体编排”第一次显得不像概念演示,而像可以落地的工程方法。
如果这篇对你有用,建议点个关注。我会持续把 GitHub 上值得用的 AI 工具拆成「最短上手闭环 + 坑点清单 + 可复用配置」,让你少走弯路。
关注微信公众号
想第一时间看到后续的工具拆解与实战更新,欢迎扫码关注公众号。

- 最新评论
- 评论区