实时换脸,开始像普通人也能用的桌面工具了:Deep-Live-Cam 值得看
- 对比与选型
- 8天前
- 22热度
- 0评论
前两天我再看一圈 AI 视频工具时,还是会下意识先过滤掉那种“演示很炸,落地很麻烦”的项目。Deep-Live-Cam 不太一样。
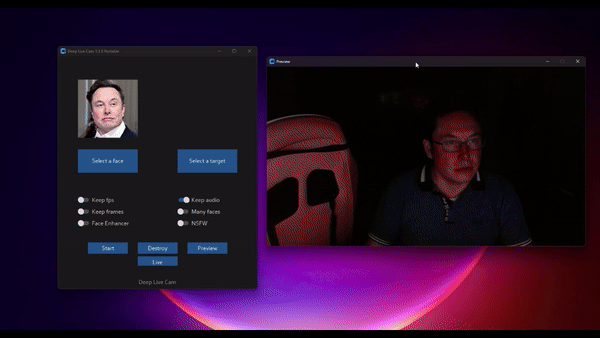
它当然不是第一个做换脸的项目,但它把一条原本要拆成模型、推理后端、摄像头、视频处理、口型修补的链路,尽量压成了一个桌面应用:选一张脸、选摄像头、点 live,就开始跑。
如果你只是想知道这项目值不值得看,我的判断很直接:值得,但别把它当成“一个深度伪造 demo”,要把它当成一套已经很接近消费级产品形态的本地工作流。
项目卡片
- 项目名:Deep-Live-Cam
- GitHub:https://github.com/hacksider/Deep-Live-Cam
- 增长信号:仓库 README 直接把自己定义成“Real-time face swap and video deepfake with a single click and only a single image”,而且最新提交就在昨天,项目仍在持续维护
- 一句话判断:它最有传播力的地方不是“能换脸”,而是把实时换脸这件事做成了普通用户也能理解的 GUI 闭环
它真正把门槛压低到了哪里
Deep-Live-Cam 的核心价值,不是底层模型突然有了新范式,而是工作流被压缩了。
README 里给的 TLDR 很直白:三步——选脸、选摄像头、按下 live。这个表述当然有宣传成分,但我回头看代码,发现它确实在围着这个目标做工程取舍。
入口就是一个很普通的 Python GUI:run.py 里直接进 modules.core.run(),UI 层则用 customtkinter 组织选择源脸、目标素材、摄像头和实时模式。你不需要自己拼 ffmpeg、手搓推理脚本,也不需要先理解一堆 notebook。
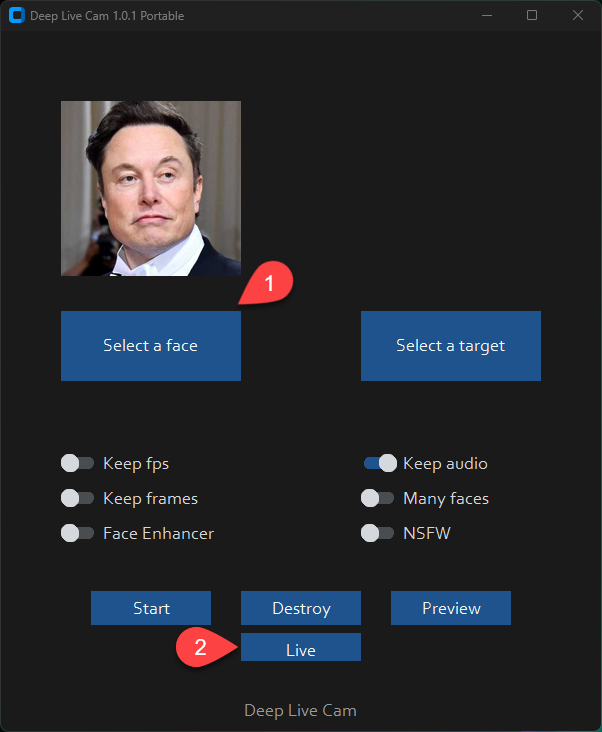
这类项目我一般先看两件事:有没有 GUI 闭环,以及命令行是不是还能独立跑。Deep-Live-Cam 两个都给了。
它的 CLI 参数里已经把关键能力都摊开了:
更关键的是,参数不是只有“换脸”这一件事。modules/core.py 里还能看到这些开关:
--many-faces:一帧里处理多张脸--map-faces:把源脸和目标脸做映射--mouth-mask:尽量保留原始嘴部运动--nsfw-filter:对不合适内容做过滤--execution-provider:在 CPU / CUDA / CoreML 等后端之间切换--frame-processor:在换脸外,再叠加 GFPGAN 或 GPEN 增强
也就是说,它不是只做出一个“演示按钮”,而是把一条完整处理链路都揉进了同一个壳里。
最值得看的设计:口型保留和多人映射
如果只看“把 A 的脸贴到 B 上”,这类项目其实已经很多了。Deep-Live-Cam 更有信息量的部分,在于它往“真实感补丁”上补了两刀。
1)Mouth Mask 不是噱头
README 里把 Mouth Mask 单独拎出来,说是“Retain your original mouth for accurate movement”。这个功能我原本以为只是一个简单遮罩,但翻代码后会发现它做得比名字细。
face_swapper.py 里会在换脸前保留原始帧副本,然后根据 106 点 landmark 计算下嘴唇和嘴周区域,生成 mouth mask,把原始嘴部区域重新贴回已经换脸后的画面里。这样做的目的很明确:脸可以换,但说话时最容易穿帮的嘴部运动尽量保留。

这一步很关键。很多换脸 demo 静态截图还行,一开口就破功。Deep-Live-Cam 至少在工程层面认真处理了这个问题。
2)Many Faces / Map Faces 说明它不只盯着单人 webcam
另一个值得看的地方,是它没有把目标场景限定成“单人直播间自拍”。
在 face_analyser.py 里,它不仅能拿单张脸,还会对视频帧里的多张脸做 embedding 聚类,找 centroid,再把不同目标脸和不同源脸做映射。README 里对应的功能名就是 Many Faces 和 Face Mapping。
这意味着它面向的不是单一玩法,而是一整类实时场景:直播、多人视频、甚至边播边换多个角色。你不一定会用到,但这说明项目作者是在把它当工具做,不只是做一个 viral demo。
它的性能思路也很实用
Deep-Live-Cam 的另一点现实感,在于它没有装作“所有机器都能轻松跑满”。
README 里明确区分了 CPU、CUDA、Apple Silicon CoreML 几条路径。代码里也能看到这种分支逻辑:
- 如果启用 CUDA,会把
OMP_NUM_THREADS设成 1,尽量减少线程争用 suggest_execution_threads()会根据不同推理后端给出不同线程建议gpu_processing.py会优先探测 OpenCV 的 CUDA 支持,有就走 GPU,没有就回 CPU fallback- Apple Silicon 路径下又专门给 CoreML 做了 provider 配置
我比较认可这种写法。它没有神化“实时”两个字,而是在不同硬件上尽量找可接受的折中。
如果你是 NVIDIA 机器,README 给的最短路径是:
如果你是 Apple Silicon,它反而写得更保守,明确提醒 Python 版本和 onnxruntime-silicon 的兼容要求。这不是漂亮话,但很有用:说明作者知道这类桌面 AI 工具最容易死在环境碎片化上。
这项目最适合谁,不适合谁
如果你想找的是:
- 一套本地跑的实时换脸 GUI
- 能快速做直播、短视频、整活 demo 的工具
- 可以从单脸扩到多人、从换脸扩到增强的工作流
那 Deep-Live-Cam 很值得试。
但如果你期待的是:
- 云端一键 SaaS
- 零安装零依赖
- 法务、风控、审核都已经产品化兜底
那它还不是这个方向。
README 虽然写了免责声明,也提到内置 NSFW 检查,并声明必要时可能加水印或停项;代码里也确实接了 opennsfw2 做过滤。但这套东西更像“作者已经意识到问题并做了第一层工程处理”,还不是完整的平台级治理。
换句话说,它已经像工具了,但还不是平台。
上手前先记这 4 个坑
如果是我自己第一次装,我会先记住这四件事:
- 先装 ffmpeg。
pre_check()里直接卡这个,没有 ffmpeg 根本不让往下走。 - 模型文件别漏。README 明确要求把
inswapper_128_fp16.onnx和 GFPGAN 模型放进models/,代码里也会在启动时检查。 - 别高估 CPU 体验。它能跑,不代表你会满意;真想用 live 模式,优先准备 CUDA 或至少可用的 CoreML 环境。
- 把它当本地实验工具,不是无风险成品。尤其涉及真人脸部素材时,授权、标注和使用场景都要自己兜住。
最后判断
我看完这个仓库之后,最大的感受不是“又一个 deepfake 项目”,而是:终于有人把实时换脸这件事,从模型演示往可操作工具又推了一步。
它当然还有很多粗糙的地方,安装依赖也不算轻,合规层面更谈不上万无一失。但就开源项目来说,它已经把最容易劝退普通人的那一段——环境、交互、后端切换、嘴部修补、多人处理——尽量收拢进了一个还能用的桌面闭环里。
这就够它值得被认真看一眼了。
如果这篇对你有用,建议点个关注。我会持续把 GitHub 上值得用的 AI 工具拆成「最短上手闭环 + 坑点清单 + 可复用配置」,让你少走弯路。
关注微信公众号
想第一时间看到后续的工具拆解与实战更新,欢迎扫码关注公众号。

- 最新评论
- 评论区