OCR,开始不只是在认字了:这个开源项目想直接还原整份文档
- Prompt / Skills / 配置
- 8天前
- 24热度
- 0评论
如果你平时接触 OCR 工具,大概率已经见过很多“把 PDF 变成文本”的方案。但真到要处理表格、公式、手写、扫描件、多栏排版,很多工具就开始掉链子:字能认出来,文档却散了。
我看完 datalab-to/chandra 后,最愿意点进去继续看的地方,就是它想做的并不只是 OCR,而是更接近一套文档理解输出层:把图片和 PDF 直接转成带版面信息的 HTML / Markdown / JSON。
项目卡片
- 项目名:Chandra OCR 2
- GitHub:https://github.com/datalab-to/chandra
- 增长信号:README 直接把它定义成 state-of-the-art OCR,并放了公开 benchmark、多语言 benchmark、样例图和可试玩的 playground
- 一句话判断:如果你在找的不是“把字抠出来”,而是“尽量把文档原样还原出来”,这个项目会比普通 OCR 更值得看
它到底在做什么
README 给的定义很直接:把图片和 PDF 转成结构化 HTML / Markdown / JSON,同时尽量保留 layout information。
这句话看着普通,但对实际使用来说差别很大。
很多 OCR 工具的终点是纯文本,或者一段顺下来的 markdown。Chandra 想做的是把文档里的结构一起带出来:
- 表格
- 数学公式
- 多栏版式
- 手写内容
- 表单和 checkbox
- 图片、图表和附带说明
- 多语言内容

如果你做的是知识库清洗、论文解析、票据/表单抽取、扫描档案数字化,这个方向明显比“纯 OCR 文本提取”更有吸引力。
为什么这个项目会让我继续往下看
原因很简单:它把“复杂文档”这件事讲得足够具体。
README 里直接列了几类它重点优化的场景:math、tables、layout、multilingual OCR、handwriting、forms。这不是泛泛说一句“高精度”,而是把最容易翻车的地方点明了。
而且仓库给了不少样例图,不是在首页只放一张漂亮 demo。你能直接看到它拿来打的题目就是复杂表格、手写数学、填写表单、多语言文档这些更接近真实业务的东西。
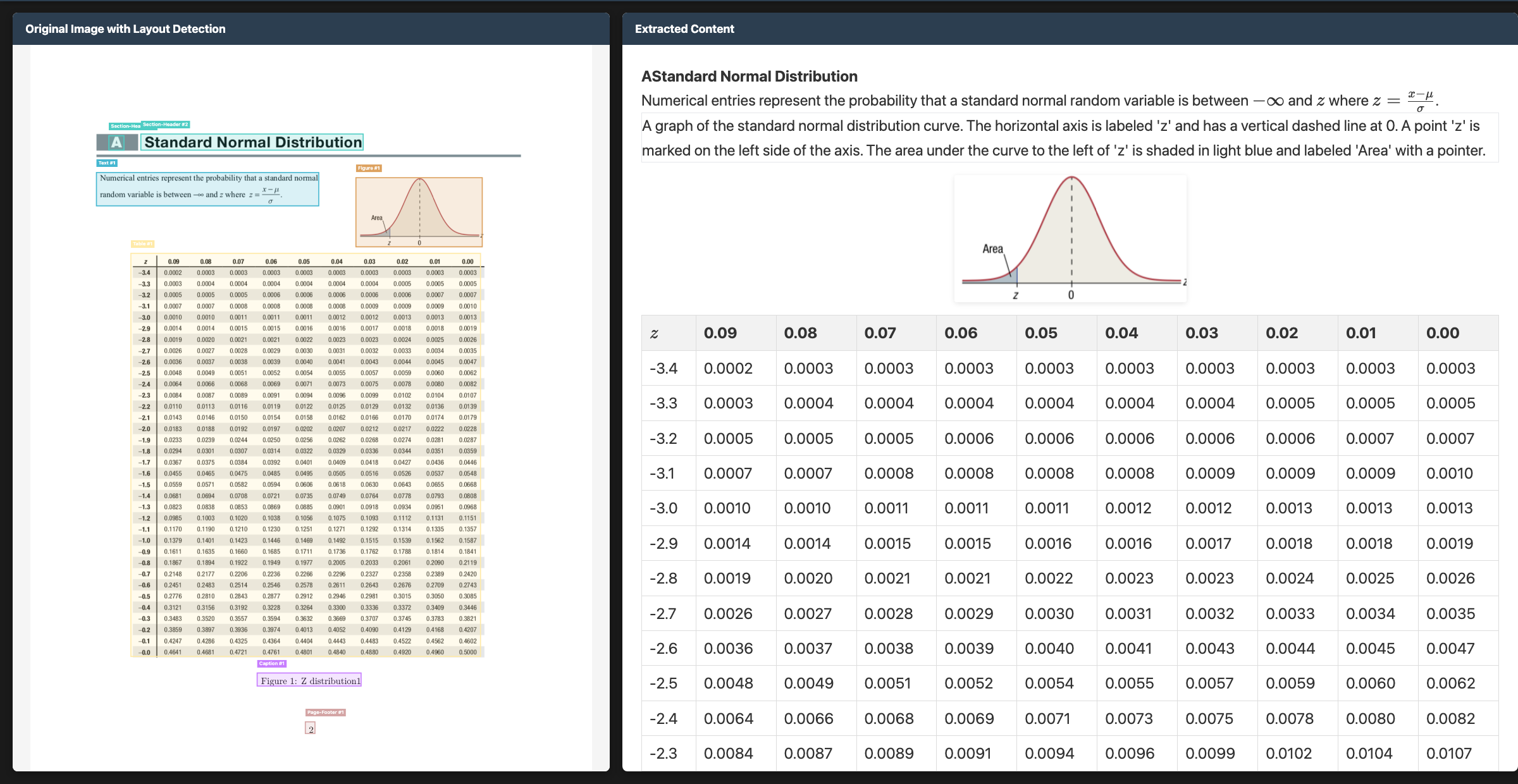
这类仓库我一般先看两件事:
- 它到底在解决哪类“难文档”问题
- 它有没有把 benchmark 和样例摊出来
Chandra 这两点都做得比较完整,所以它不太像一个只靠口号的 OCR demo。
最有信息量的地方:它想直接给你结构化结果
从 CLI 和输出结构看,这项目的落点很清楚。
装完以后,最短路径是:
如果你想本地直接跑 HuggingFace 模型,也可以:
仓库里把输出结构也写得很明白:每个文件会生成一个子目录,里面至少有:
xxx.mdxxx.htmlxxx_metadata.json- 以及抽取出来的图片
这点很重要。因为很多 OCR 工具只给一个文本结果,后面还得自己重新拼结构;Chandra 则把 markdown、html、metadata 一起给出来,明显更适合接到后续处理链路里。
它为什么更像“文档理解工具”
原因在于它不是只给一个识别接口,而是把几种实际部署路径都想到了。
README 里给了两种 inference mode:
- local HuggingFace
- remote vLLM server
默认方法是 vllm。CLI 里还能控制:
--page-range--max-output-tokens--max-workers--include-images--include-headers-footers--batch-size
这说明它并不是只想做一个演示网页,而是已经往批处理、并行处理、输出裁剪这些真实使用场景走了。
另外一个我会多看一眼的点,是它连 chandra_app 和 chandra_vllm 两条入口都准备了:一个偏试玩和单页交互,一个偏服务化部署。这个分层比很多“本地脚本 + README 截图”项目成熟得多。
Benchmark 也不是只挑最好看的讲
README 里放了两类 benchmark:
- 对标
olmocr的公开 benchmark - 自建的 multilingual benchmark
从表里看,Chandra 2 在自家总分上写的是 85.9 ± 0.8,高于 olmOCR 2 的 82.4,也明显高于 Marker v1.10.0、Deepseek OCR、Mistral OCR API、GPT-4o (Anchored) 这些方案。
在 43 语言表里,README 给的平均分是:
Datalab API:80.4%Chandra 2:77.8%Gemini 2.5 Flash:67.6%GPT-5 Mini:60.5%
在更完整的 90 语言 benchmark 里,FULL_BENCHMARKS.md 写的是:
Chandra 2:72.7% ± 1.2%Gemini 2.5 Flash:60.8% ± 1.3%
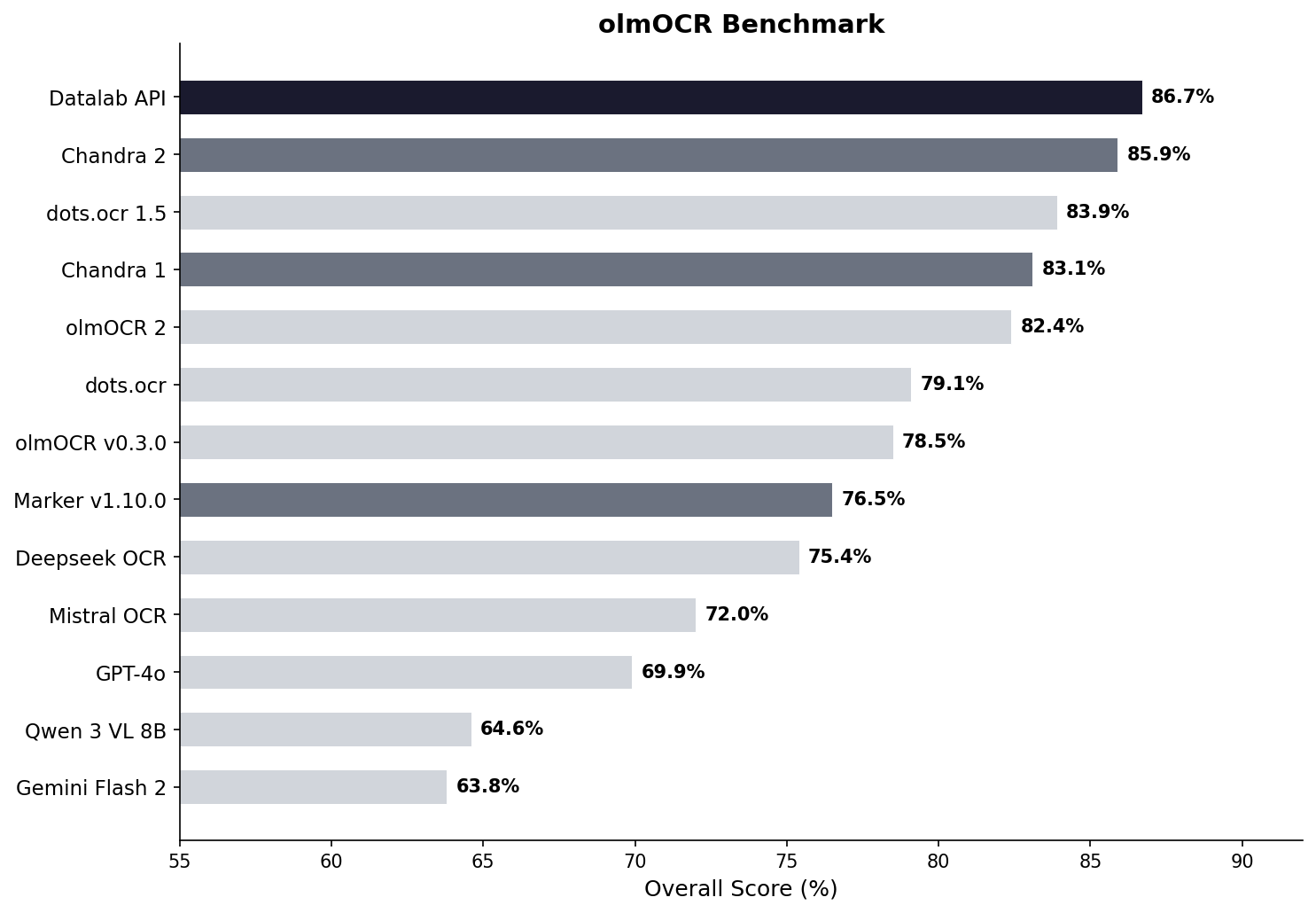

当然,这些 benchmark 主要还是仓库自己整理的结果,阅读时要保留一点常识:它能说明方向和能力边界,但不等于你的业务文档上来就会同样表现。
谁适合试,谁别急着试
如果你现在在做这些事,Chandra 很值得上手:
- PDF / 图片转 markdown
- 扫描件和复杂文档数字化
- 多语言 OCR
- 表格、公式、表单抽取
- 给下游 LLM / RAG 提供更干净的文档输入
但如果你要的是:
- 超轻量、本地 CPU 就能舒服跑
- 完全无环境成本
- 商业上没有额外许可顾虑
那这项目就不一定是最省心的选择。
一方面,它推荐的主路径里有 vLLM;另一方面,模型权重许可证是修改版 OpenRAIL-M:研究、个人使用和融资/营收低于 200 万美元的创业公司可免费,不能和它的 API 形成竞争用途。 这意味着你把它当开源代码拿来研究没问题,但真到商用落地,最好把许可边界先看清楚。
最后判断
我会把 Chandra 归到一类很值得写的项目里:它不是把 OCR 再卷高一点,而是在把 OCR 的交付结果往“结构化文档”推进。
这件事听起来不像一个很新的口号,但落到表格、公式、手写、多语言和复杂版面时,差别会非常实际。对很多文档 AI 流程来说,前面那一步如果拿到的已经不是散乱文本,而是更完整的 HTML / Markdown / JSON,后面的抽取、检索和生成都会轻松很多。
如果你最近在找一个更像“文档理解层”的 OCR 项目,Chandra 是值得认真看一眼的。
如果这篇对你有用,建议点个关注。我会持续把 GitHub 上值得用的 AI 工具拆成「最短上手闭环 + 坑点清单 + 可复用配置」,让你少走弯路。
关注微信公众号
想第一时间看到后续的工具拆解与实战更新,欢迎扫码关注公众号。

- 最新评论
- 评论区