Claude Bug Bounty:把漏洞赏金的 recon、验证、报告塞进 Claude
- Prompt / Skills / 配置
- 11天前
- 34热度
- 0评论
- Claude Bug Bounty:把漏洞赏金的 recon、验证、报告塞进 Claude
如果你平时看 bug bounty 工具,大多数项目解决的只是其中一小段:要么做 recon,要么跑扫描,要么帮你整理报告。
claude-bug-bounty 讲的是另一件事:把漏洞赏金里最常见的几步——资产收集、线索分类、发现验证、报告生成——接成一条完整工作流,然后交给 Claude Code 调度。
所以这篇文章的重点很简单:它不是“AI 自动挖洞”,而是一个面向 bug bounty 场景的 Claude 插件工作台。
先看项目卡:
项目名:claude-bug-bounty GitHub:https://github.com/shuvonsec/claude-bug-bounty 增长信号:2026 年 3 月完成 v2.x 重构,从单文件技能升级成完整插件架构 一句话判断:它最有价值的地方,不是“自动挖洞”,而是把 bug bounty 里最浪费时间的几个环节系统化了。

这个项目把自己定义成一个面向 Claude Code 的漏洞赏金插件,重点是 Web2 + Web3、从 recon 到 report 的完整流程。
它到底是什么
从仓库结构看,这已经不是普通脚本集合,而是一个完整的 Claude Code 插件:
- 7 个 skills
- 8 个 slash commands
- 5 个 agents
- 一组始终生效的 hunting rules
- 以及保留下来的 Python / Shell 工具链
我看这类项目,通常先看目录是不是自洽。这个仓库在这点上做得不错:skills/、commands/、agents/、rules/ 和根目录脚本之间是连起来的。
它的核心思路也很明确:
不是让大模型代替安全研究员,而是让它按方法论去调度 recon、验证和报告。
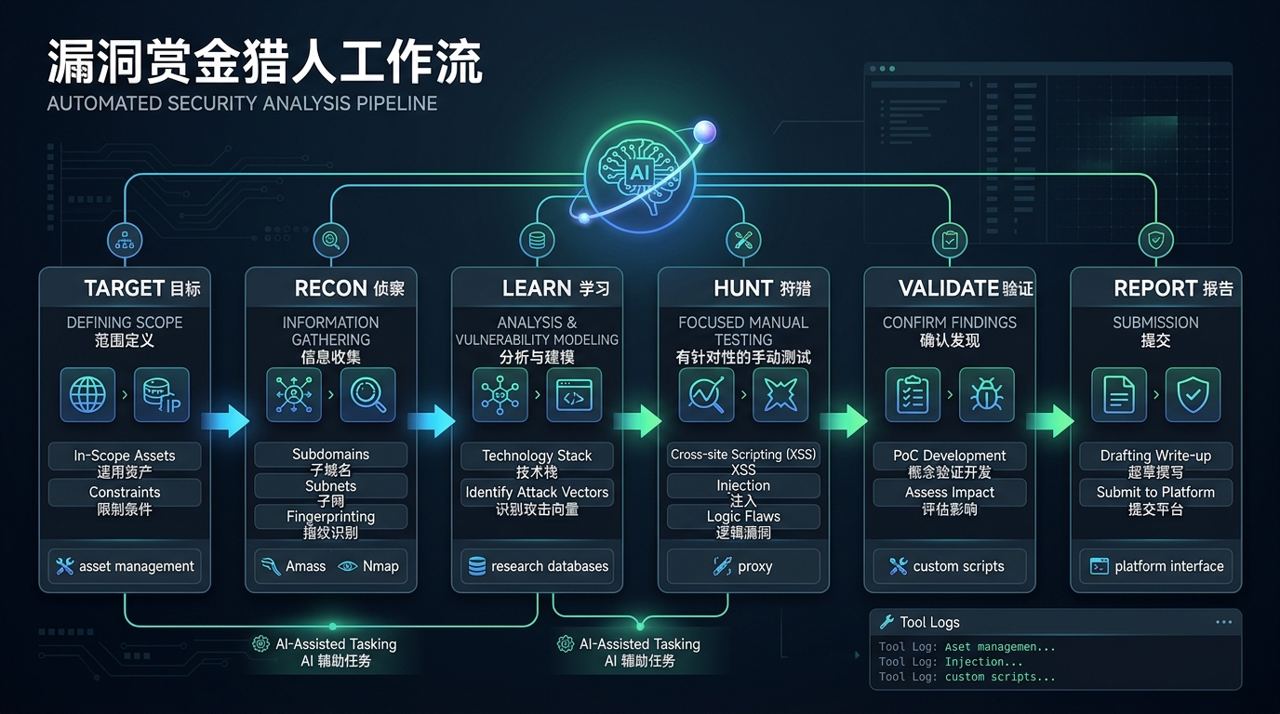
README 里的主流程是 Target → Recon → Learn → Hunt → Validate → Report,重点是编排,而不是单点扫描。
为什么这个思路值得看
1. recon 被固定成了一条标准流水线
/recon 不是一句空口号,README 和 commands/recon.md 里写了完整步骤:
- Chaos API、subfinder、assetfinder 做子域名枚举
- dnsx + httpx 找活跃站点和技术栈
- katana、waybackurls、gau 拉 URL
- gf 按 XSS、SSRF、IDOR、SQLi 等方向做分类
- nuclei 跑已知漏洞和常见错误配置
这件事的意义在于,它没有把“AI 驱动”理解成让模型直接上来猜,而是先把最基础的 recon 管道做扎实。
2. 它很强调“尽快杀掉弱发现”
这是我觉得这个仓库最值钱的地方。
它单独做了 triage-validation 技能和 /validate 命令,核心是两层门禁:
- 7-Question Gate
- 4 个 pre-submission gates
规则很硬:
- 不能一步步现场复现,kill
- 不在 scope,kill
- 需要攻击者拿不到的高权限,kill
- 只有理论可能、没有真实影响证明,降级甚至 kill
- 命中 never-submit list,直接停
这套设计抓得很准。bug bounty 最贵的资源不是扫描器,而是时间。很多人不是不会跑工具,而是会在一个不值得报的点上消耗太久。
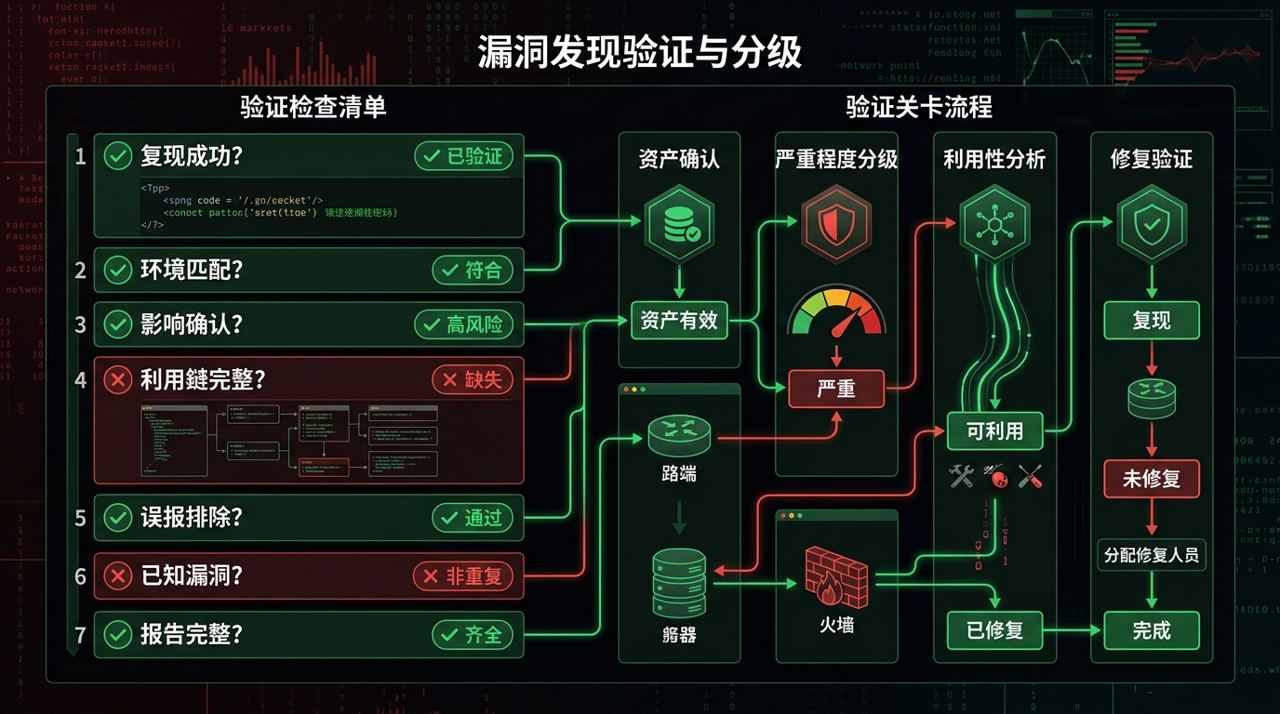
/validate 文档把提问和门禁写得很具体,目标就是尽早砍掉不值得继续写报告的弱发现。
3. 报告写作被单独抽成 agent
仓库里有 report-writer agent,定位很清晰:给 HackerOne、Bugcrowd、Immunefi 这类平台生成更像真实提交的报告。
它的写作规则也很务实:
- 不写
could potentially - 开头先写攻击者拿到了什么
- 必须展示真实数据,不接受只有
200 OK - 自带 CVSS 3.1 和平台模板
这背后反映的是一个现实:同一个洞,证据组织和叙述方式不同,结果会差很多。
它补的其实不是“自动化”,而是工作流
从 CHANGELOG.md 看,v2.0.0 开始这个仓库从单体 SKILL.md 重构成插件体系;v2.1.0 又继续补漏洞类别和 payload。
这个变化的意义不只是“文件拆细了”,而是模型终于可以按任务加载知识:
- recon 看
web2-recon - 挖某类漏洞看
web2-vuln-classes - 写报告看
report-writing - 判断值不值得提交通知看
triage-validation
这比把所有经验全塞进一个长提示词里实用得多,也更像真实团队的分工方式。
另外,它覆盖的方向也有明显偏好。除了 IDOR、XSS、SSRF、SQLi 这些常规类型,它还强调:
- 业务逻辑
- Race condition
- HTTP smuggling
- Cache poisoning
- MFA bypass
- SAML / SSO
- LLM / Agentic AI 安全测试
这说明它更在意那种自动扫不出来,但一旦成立价值不低的方向。
上手门槛不低,但路径很清楚
安装方式很简单:
install.sh 做的事情也很直接:
- 把
skills/*/SKILL.md复制到~/.claude/skills/ - 把
commands/*.md复制到~/.claude/commands/
但真正的门槛不在安装,而在环境。
它依赖 Python、bash、node、jq、go,还要配 subfinder、httpx、dnsx、nuclei、katana、gau、dalfox、sqlmap 这类工具;另外 recon 还要准备 CHAOS_API_KEY。
所以这不是一个零配置玩具,而更像给已经在 bug bounty 场景里工作的人准备的 workflow 增强器。
我对它的判断
我不会把它吹成“漏洞赏金 autopilot”。真实漏洞还是要靠研究者自己验证,scope、影响证明、PoC 这些也不会因为接了 AI 就自动变简单。
但这个仓库方向是对的。
它抓住了 bug bounty 里一个经常被忽略的问题:真正拖慢产出的,往往不是不会扫,而是不知道什么时候该停、什么时候该换、什么时候一个点根本不值得写。
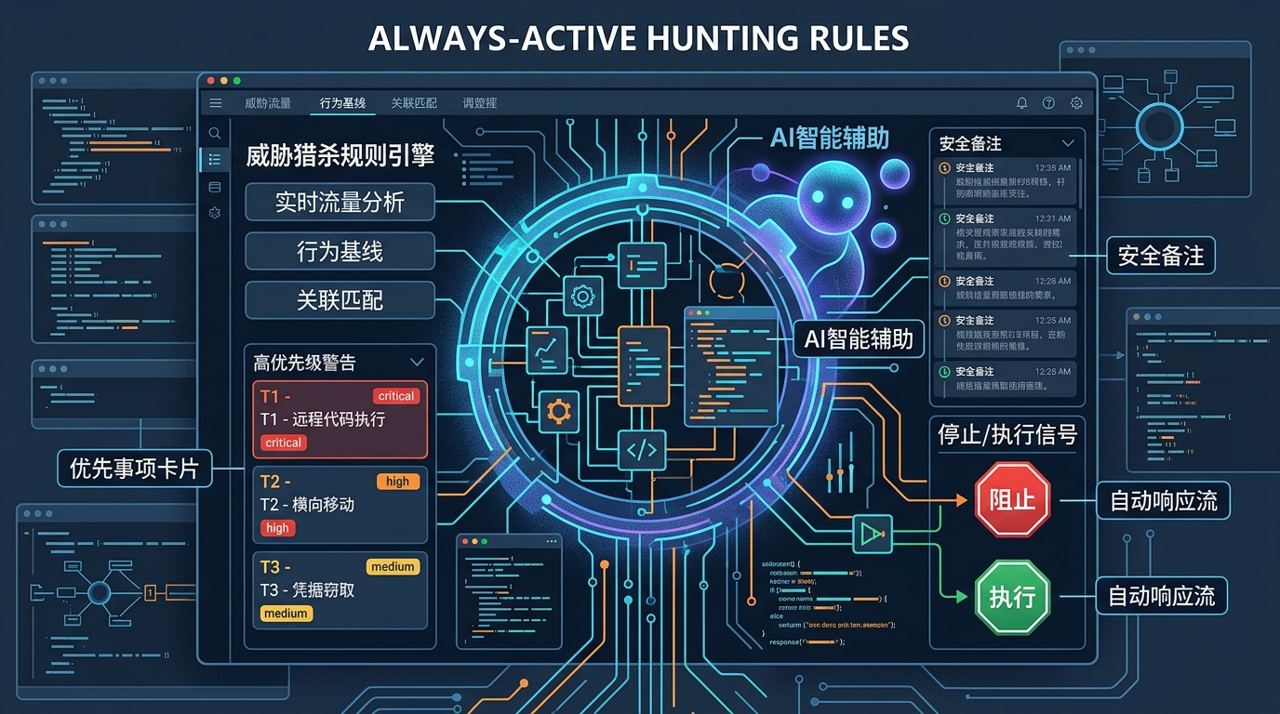
规则层是这个项目很关键的一部分:它试图把“什么时候该停、什么时候不能报”写成始终生效的约束。
如果你已经有基础 recon 工具链,claude-bug-bounty 值得看;它不是替你找洞,而是帮你把混乱的流程收束成一个更像工作台的东西。
如果这篇对你有用,建议点个关注。我会持续把 GitHub 上值得用的 AI 工具拆成「最短上手闭环 + 坑点清单 + 可复用配置」,让你少走弯路。
关注微信公众号
想第一时间看到后续的工具拆解与实战更新,欢迎扫码关注公众号。

- 最新评论
- 评论区