3.95 万 Star,ByteDance 的 DeerFlow 为什么不是又一个 AI Agent Demo
- 对比与选型
- 12天前
- 70热度
- 0评论
- 3.95 万 Star,ByteDance 的 DeerFlow 为什么不是又一个 AI Agent Demo
如果你最近刷到 DeerFlow,很容易先把它归类成“ByteDance 开源的又一个 Deep Research 项目”。这个判断不算错,但只看这一层,会低估它真正想做的东西。
我看完 README、配置文档和几段核心代码后的感觉是:DeerFlow 2.0 现在更像一个 super agent harness。它不是只演示一次搜索和报告生成,而是在认真补一套 agent 长时间干活需要的基础设施:skills、sub-agents、sandbox、memory、MCP、消息通道,还有把这些能力串起来的运行时。
先放项目卡。
项目卡
- 项目名:DeerFlow
- GitHub:https://github.com/bytedance/deer-flow
- 增长信号:截至 2026-03-24,GitHub 约 3.95 万 Star / 4644 Fork,README 里提到它在 2026-02-28 拿过 GitHub Trending #1。
- 一句话判断:这不是“再做一个会搜网页的 Agent”,而是在把 Agent 运行时做成可扩展底座。
DeerFlow 到底是什么
README 对它的定义很直接:Deep Exploration and Efficient Research Flow,但 2.0 的定位已经从 deep research framework 改成了 super agent harness。
这个变化不是包装词。仓库里把话说得很清楚:2.0 是一次 ground-up rewrite,而且和 1.x 不共用代码;旧版 Deep Research 框架还留在 main-1.x 分支继续维护,主线已经转去 2.0。也就是说,团队并不是在老项目上小修小补,而是换了一个更大的目标。
我会这么理解它:
- 前台看起来是一个聊天式 Agent 应用
- 后台其实是一套运行时
- 这套运行时重点不在“回答得多聪明”,而在“能不能把复杂任务拆开、执行、保存上下文、接工具、接外部渠道,然后持续跑下去”
这也是它和很多 demo 型 Agent 项目最不一样的地方。
它补的是哪一层
很多 Agent 项目停在这一步:模型 + 搜索 + 网页抓取 + 一个漂亮 UI,然后演示“帮我研究 XX”。第一次看很惊艳,真放进日常工作,很快就会撞上问题:上下文怎么压?任务怎么拆?文件放哪?工具怎么扩?换渠道怎么接?
DeerFlow 基本是在补这整层运行时。
从官方架构图能看出来,它把系统拆成了三块:
- LangGraph Server:负责 agent runtime、thread state、SSE streaming
- Gateway API:负责 models、skills、MCP、uploads、artifacts 这些非对话层能力
- Frontend:Next.js 聊天界面和工作台
外面再用 Nginx 统一代理到 2026 端口。这个拆法很工程化:前端、运行时、配置面、外部扩展面都分开了,不是把所有逻辑糊在一个 Web App 里。
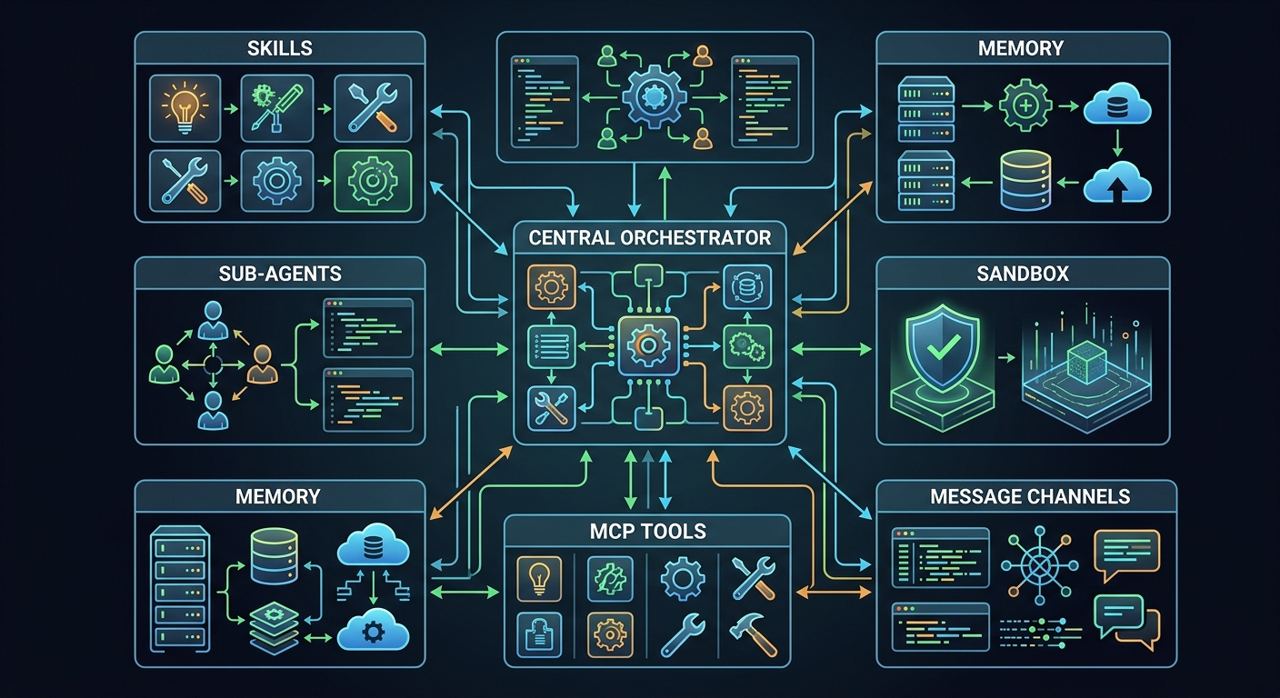
DeerFlow 更值得关注的是这套运行时本身:orchestrator、skills、sub-agents、memory、sandbox、MCP 和消息通道被组织进了同一张工作底座里。
最值得看的 5 个点
1)Skills 不是提示词附件,而是能力装配方式
DeerFlow 把 skill 当成结构化能力模块,不只是“往 prompt 里塞一段说明”。
仓库里的 skills/ 分成 public 和 custom 两类,每个 skill 都是一个 SKILL.md,可以带 frontmatter 元数据。加载器会扫描目录、解析 skill 文件,再结合 extensions_config.json 判断启用状态。
这个设计的现实意义很直接:工作流知识可以单独沉淀,skill 也能启停、替换、按任务渐进加载,避免上下文一上来就塞满。
README 里也专门强调了一点:skills 是 progressively loaded。我很认同。很多系统喜欢“全能力一次注入”,看上去全能,实际上特别烧上下文,也更容易让模型乱用能力。
2)Sub-agent 真的是运行时一等公民
不少项目会说自己支持 multi-agent,但真实情况常常只是写几个角色 prompt。
DeerFlow 不一样。subagents/executor.py 里有独立的 SubagentExecutor、状态枚举、后台任务池、超时控制和结果回收逻辑。子代理不是概念角色,而是可以在后台真正跑起来的执行单元。
它先补的是这些基础问题:
- 状态:
PENDING / RUNNING / COMPLETED / FAILED / TIMED_OUT - 并发:调度池和执行池拆开
- 超时:单个 sub-agent 可设置 timeout
- 结果:保留
ai_messages和最终结果,便于主代理回收
这就不是“一次响应里顺手演一下 multi-agent”了,而是在按长任务运行时来设计。
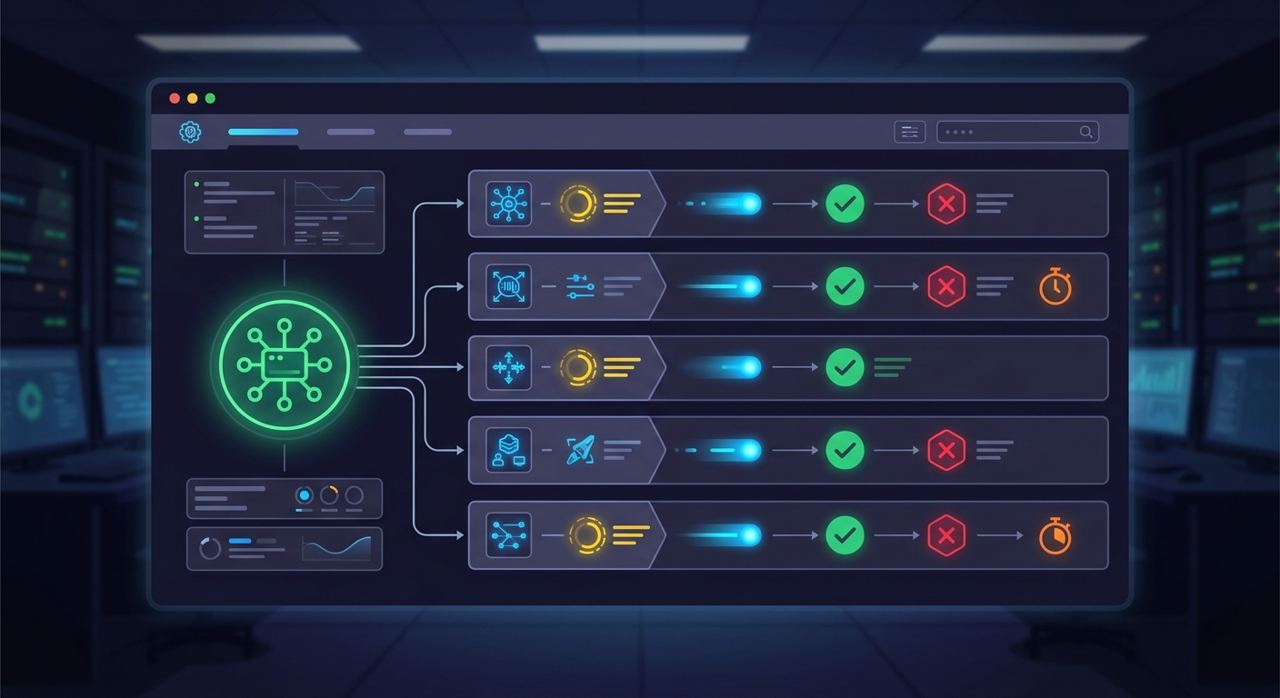
这张图对应的是 DeerFlow 对 sub-agent 的处理方式:有主代理、有并发执行、有状态流转,不是几个角色 prompt 轮流说话。
3)Sandbox 不是附加项,而是默认工作环境
README 里有一句话写得很对:区别不在于“有工具的聊天机器人”,而在于“有没有真正的执行环境”。
DeerFlow 默认就把 sandbox 当成核心能力来讲,而且不是只有一种模式:
- 本地执行
- Docker 容器执行
- 通过 provisioner 跑到 Kubernetes Pod
如果你只是做 demo,本地执行当然最快;但如果你真想让 agent 持续读写文件、跑命令、处理上传产物,没有隔离层后面基本都会出问题。
它这里连虚拟路径映射都整理好了:工作区、上传目录、输出目录都走统一映射。这一点看着不起眼,实际特别重要。因为一旦你要接前端上传、产物预览、任务复跑、线程删除,路径体系乱了,后面全是补丁。
4)Memory、Summary、Title 都被做成中间件
我一般会先看一个 Agent 系统怎么处理那些“不是核心推理、但必须长期存在”的能力。
DeerFlow 的做法是中间件化。在 lead_agent/agent.py 里,主代理的 middleware 链已经把 Summarization、Title、Memory、ViewImage、Clarification、LoopDetection、Todo、SubagentLimit 这些能力串好了。
这样做的好处很直接:边界清楚,后面替换、增删、调顺序都相对可控。尤其是 summary + memory 这对组合,很像真正的运行时思路:前者解决当前 session 不爆 context,后者解决跨 session 还能保留用户信息和偏好。
5)它把外部接入也想明白了
DeerFlow 不是只做一个网页入口。
README 和配置文档里已经把 Telegram、Slack、Feishu/Lark 三类消息渠道接进来了,而且都是按各自的传输方式去配:Telegram long-polling、Slack Socket Mode、Feishu WebSocket。
MCP 这边也不是点到为止。extensions_config.json 支持 stdio / sse / http 三种 MCP server 接入方式,HTTP/SSE 还补了 OAuth token 获取和刷新逻辑。
这说明它想做的是一套可以被嵌进网页、IM 和外部工具体系里的 agent 基座,而不是一个单入口 demo。
怎么上手最合理
如果你只是想快速看懂 DeerFlow,不建议一上来就研究所有特性。我会按这个顺序:
最短上手闭环
git clone https://github.com/bytedance/deer-flow.git- 在项目根目录执行
make config - 按
config.yaml先配至少一个模型 - 在
.env里补 API Key - 先走官方推荐路径:
make docker-start - 打开
http://localhost:2026
如果不想进 Docker,也能走本地开发模式,但前提是你先把依赖环境补齐:Node.js 22+、pnpm、uv、nginx。仓库也给了 make check 和 make install。
还有个细节值得看:README 已经把 Codex CLI 和 Claude Code OAuth 当成模型 provider 写进配置示例了,不只是传统 API provider。目标用户显然不只是调用云端模型 API 的人,也包括已经在日常用 Codex、Claude Code 这类 CLI agent 的开发者。
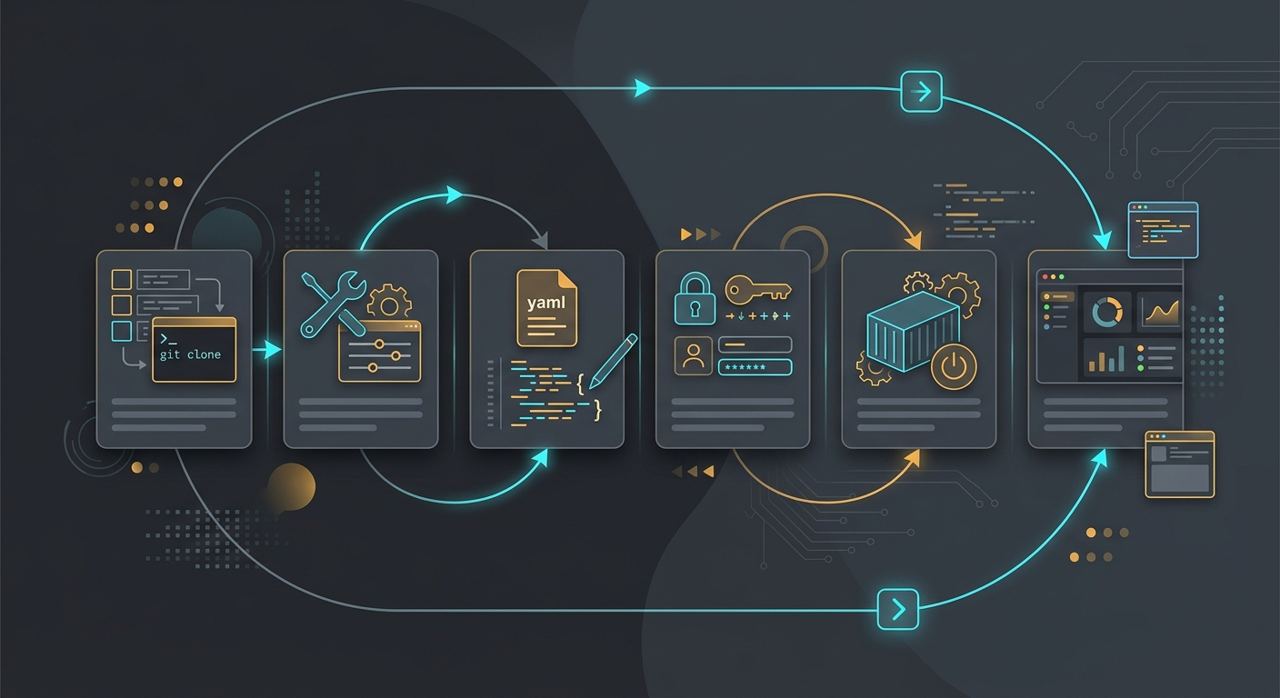
最短上手闭环对应的 6 个动作:拉仓库、生成配置、填模型、补 key、启动服务、打开本地工作台。
它适合谁,不适合谁
适合的人
- 想搭自己的 Agent 工作台,而不是只想调用一个封闭 SaaS
- 已经在折腾 LangGraph / MCP / skills / sandbox 这些基础设施
- 需要让 Agent 真正处理文件、消息、长任务、多阶段任务
- 希望从 deep research 往更通用的 agent runtime 走
不太适合的人
- 只想“一条命令起一个能搜网页的研究助手”
- 不关心运行时、权限、扩展、沙箱、配置,只在乎现成结果
- 不打算自己维护部署和模型配置
说白了,DeerFlow 不是那种“零配置、两分钟就幸福”的产品。它更像一个已经帮你搭好骨架的 agent 系统底座。这个项目的价值,也恰恰在这里。
最后一句判断
我最后会记住 DeerFlow,不是因为它把“Deep Research”又讲了一遍,而是因为它在认真回答一个更难的问题:当 Agent 不再只是一次性对话,而要长期接任务、拆任务、跑工具、接外部渠道时,底座应该怎么搭。
这也是为什么它最近涨得这么快。很多人表面上是在找“下一个好用的 Agent 项目”,实际上是在找一套能承载更复杂工作流的基础设施。DeerFlow 刚好踩在这个点上。
如果这篇对你有用,建议点个关注。我会持续把 GitHub 上值得用的 AI 工具拆成「最短上手闭环 + 坑点清单 + 可复用配置」,让你少走弯路。 ��路。
关注微信公众号
想第一时间看到后续的工具拆解与实战更新,欢迎扫码关注公众号。

- 最新评论
- 评论区