AutoResearchClaw:AI 写论文,开始碰真问题了
- Prompt / Skills / 配置
- 2026-03-19
- 49热度
- 0评论
- AutoResearchClaw:AI 写论文,开始碰真问题了
最近“AI 写论文”类项目很多,口号也差不多:从 idea 到 paper,全自动科研,一键生成研究成果。
这类项目我现在会先看三件事:引用是不是真的,实验有没有真的跑,失败之后系统怎么处理。
AutoResearchClaw 让我停下来的,也正是这三件事。
它当然也在写论文,但和很多“论文生成器”不太一样的地方在于,它没有把最麻烦的部分藏起来。它试图把文献、实验、执行、修复和论文交付放进同一条链路里。
先看项目本身
- 项目名:AutoResearchClaw
- GitHub:https://github.com/aiming-lab/AutoResearchClaw
- 我的判断:它不像一个“论文写作器”,更像一个试图把研究任务整条推下去的自动化管道。
你给它一个研究想法,它去查文献、整理背景、生成假设、写实验代码、跑结果、整理图表、生成论文,最后把 LaTeX、BibTeX、代码和图一起交出来。
光看这段介绍,其实还是很容易把它归到“AI 自动科研”的大词项目里。
但它和很多同类仓库不一样的一点,是没有只停在“生成一篇像论文的文字”。它试图往前多跨几步,把研究流程里最费时间、也最容易翻车的部分接进去。
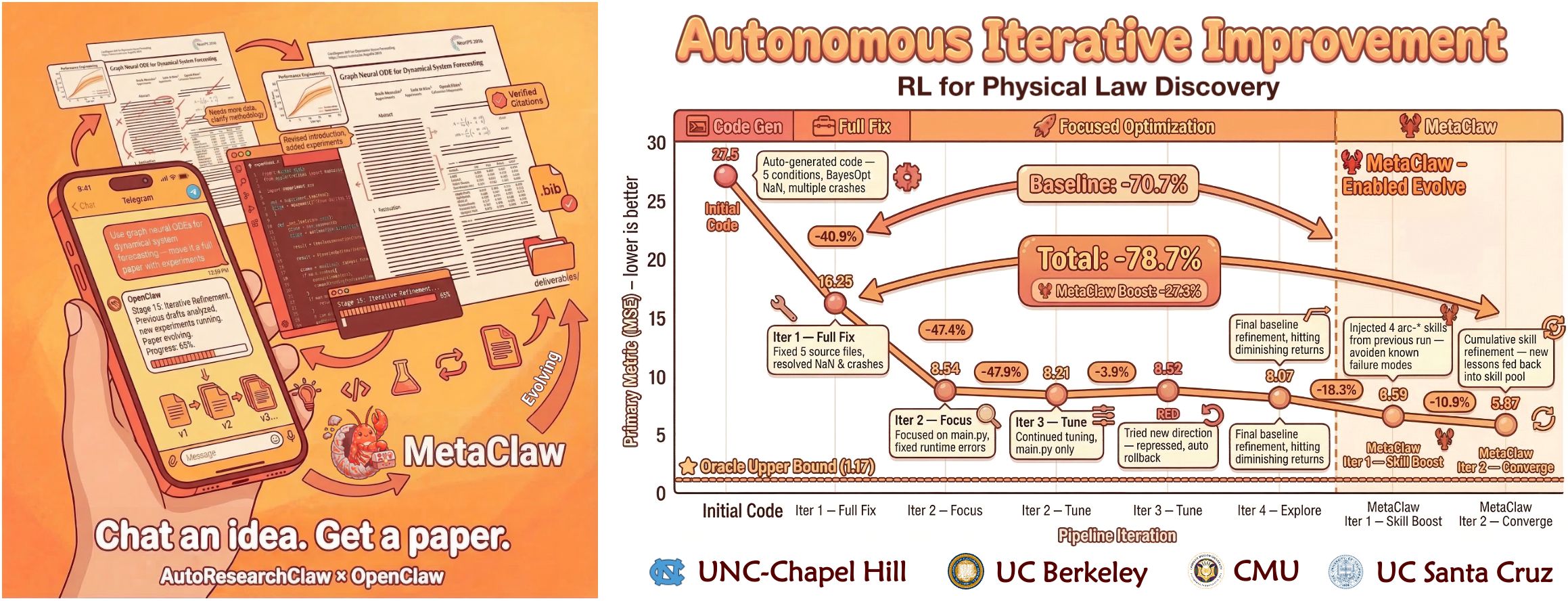
官方流程图。至少能看出来,它想处理的不是单点写作,而是一整条链路。
这项目最值得看的,不是“会写”,而是“没回避失败”
写论文这件事最容易做假的地方,恰好不是文风,而是过程。
你让模型写摘要、related work、方法介绍,它很快就能拼出一篇像样的东西。可真正难的不是“写得像”,而是下面这些:
- 文献有没有乱编
- 引用能不能核验
- 实验代码能不能跑
- 跑挂了之后能不能继续修
- 结果不好时系统会不会转向
- 最后的论文到底是文本包装,还是研究过程留下来的交付物
很多项目到这里就开始含糊了,因为这部分没法只靠措辞糊过去。
AutoResearchClaw 值得多看一眼,就是因为它没有绕开这些脏活。只要一个系统认真处理失败,它就已经和“高配写稿器”不是一类东西了。
23 个阶段,不是重点
老实说,“23 个阶段”这种表述本身并不会打动我。
阶段数很容易变成产品叙事。重要的不是写了 23 个还是 17 个,而是这些阶段是不是只是把 prompt 拆细了,还是它们真的承担了不同职责。
从仓库描述看,前面在做文献和背景知识处理,中间在做假设、实验与代码,后面在做结果整理、论文撰写和引用校验。更重要的是,它不是一条线跑到底就算完,而是承认中间会失败、会返工、会调整。
这才是更接近真实研究工作的地方。
我最后是被两件事说服的:引用和实验
引用
AI 写学术内容,最容易露馅的地方就是参考文献。
标题像真的,作者像真的,年份像真的,会议名也像真的,结果一搜,根本没这篇东西。模型很擅长把“学术引用的外形”做出来,但这不等于它真的找到了文献。
所以一个自动化研究系统值不值得信,引用处理几乎是一道门槛。
AutoResearchClaw 至少没有把引用当作文风的一部分来处理,而是把它当成要单独验证的对象。文献来源走的是实际学术数据库,后面还有多层校验逻辑。这里一旦偷懒,后面整篇论文都会变成表演。
实验
实验执行是另一个分水岭。
很多“AI 写论文”项目,最后其实是写作工具。它们能把 methodology 和 results 写得很完整,但实验结果本身未必真的跑过。最差的情况,是系统一边没跑,一边还写得像真的跑出来了一样。
AutoResearchClaw 至少想把代码放进真实执行环境里跑,包括沙盒、容器之类的模式,报错后再尝试修复,把日志、图表、指标一起收回来。
我更在意这个。因为真实工作里,最耗时间的从来不是“怎么把结果写成论文腔”,而是环境、基线、报错和返工。
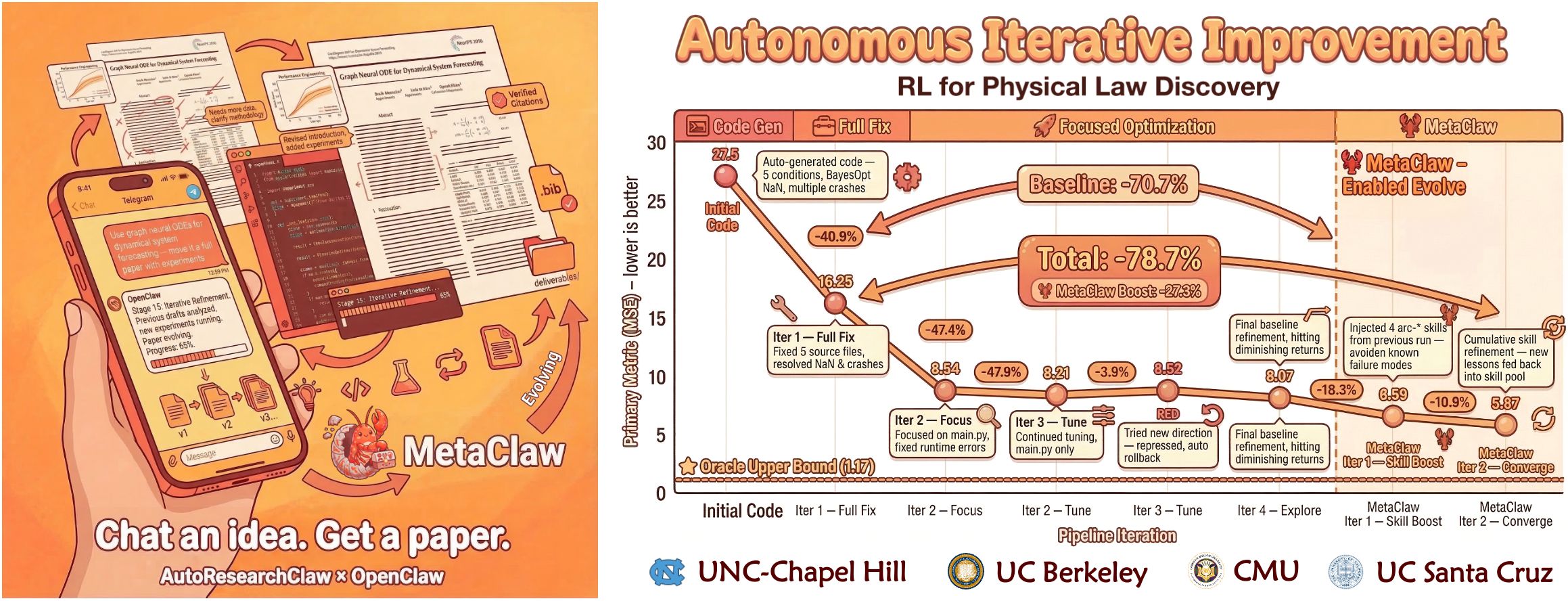
我更在意这种图背后有没有真实执行链路,而不是它把流程图画得多完整。
如果你只想快速试一下
这项目的启动方式其实不复杂:
如果只是想判断值不值得继续投入,我不建议你一上来就拿特别大的研究题目去跑。
更好的试法,是先拿一个边界清楚、评价指标明确、实验规模可控的小问题。这样你更容易看出来:它到底是在真的推进流程,还是只是把表面文章补齐。
谁会真正用得上它
我觉得最适合这类系统的,不是那些想一键出成果的人,而是本来就在做研究探索、只是被流程拖慢的人。
比如:
- 脑子里有很多方向,想先筛掉一批明显不值得做的
- 经常要花很长时间查文献、整理背景、起实验基线
- 想把研究流程拆成更工程化、更可复用的链路
- 需要快速产出一版能继续改的 draft,而不是从空白页开始
但如果你期待的是,它直接替你做出真正有原创性的研究判断,或者一轮就生成能投顶会的论文,那最好别想太多。
它现在更像一个能把脏活累活接过去一部分的系统,不是学术奇迹机。
最后说我的判断
如果你问我,这项目值不值得看,我会说:值得。
不是因为它已经解决了“自动科研”这件事,也不是因为口号取得多大。
而是因为它没有只停在最容易装出来的那一层。它开始认真碰那些真正麻烦的部分:引用、实验、失败、修复、返工。
很多项目都在证明 AI 很会说。 但真正有意思的方向,可能确实是另一边:不是谁更会写一段像样的话,而是谁能把一件复杂的事往前真的推一点。
如果这篇对你有用,建议点个关注。我会持续把 GitHub 上值得用的 AI 工具拆成「最短上手闭环 + 坑点清单 + 可复用配置」,让你少走弯路。
关注微信公众号
想第一时间看到后续的工具拆解与实战更新,欢迎扫码关注公众号。
