Deep Agents 火了,但它真正值得看的不是 Agent,而是这套工作台
- Prompt / Skills / 配置
- 2026-03-18
- 64热度
- 0评论
- 项目名:Deep Agents
- GitHub:https://github.com/langchain-ai/deepagents
- 一句话判断:它更像一套 agent 工作台,而不是一个孤立的 agent demo。
- 热度:GitHub 相关结果里可见 14k Star 级别热度
- 活跃度:本地仓库近 30 天有 417 条提交,更新非常快
现在很多 agent 项目都在比“会不会调工具”,Deep Agents 比较不一样:它先把 planning、文件系统、shell、sub-agent 和 CLI 这套工作台搭好了。
所以它真正值得看的,不是又做了一个 Agent,而是把复杂任务怎么组织这件事,先做成了默认能力。
项目卡片
- 项目名:Deep Agents
- GitHub:https://github.com/langchain-ai/deepagents
- 一句话判断:它更像一套 agent 工作台,而不是一个孤立的 agent demo。
- 热度:GitHub 相关结果里可见 14k Star 级别热度
- 活跃度:本地仓库近 30 天有 417 条提交,更新非常快

如果把很多 agent 项目理解成“会说话的工具调用器”,Deep Agents 更像是把完整工作台先搭出来了。
它到底做了什么
官方给自己的定位很直接:The batteries-included agent harness。
翻成人话就是:你不用从零把 agent 的骨架一点点拼起来,它先给你一套能工作的默认组合。
从 README 看,默认能力包括:
write_todos:拆任务、跟进度- 文件系统工具:
read_file、write_file、edit_file、ls、glob、grep execute:直接跑 shelltask:把子任务委派给 sub-agent- 自动摘要、长输出落盘:避免上下文一路膨胀
这也是它和很多 agent demo 的差别。
很多 demo 解决的是“模型能不能调工具”;Deep Agents 解决的是“模型怎么把一件复杂任务持续做下去”。
核心不是单个工具,而是 planning、文件系统、执行环境和 sub-agents 被组合成了同一套工作流。
为什么这套思路更重要
真正让 agent 难用的,通常不是模型不够聪明,而是工作方式太浅。
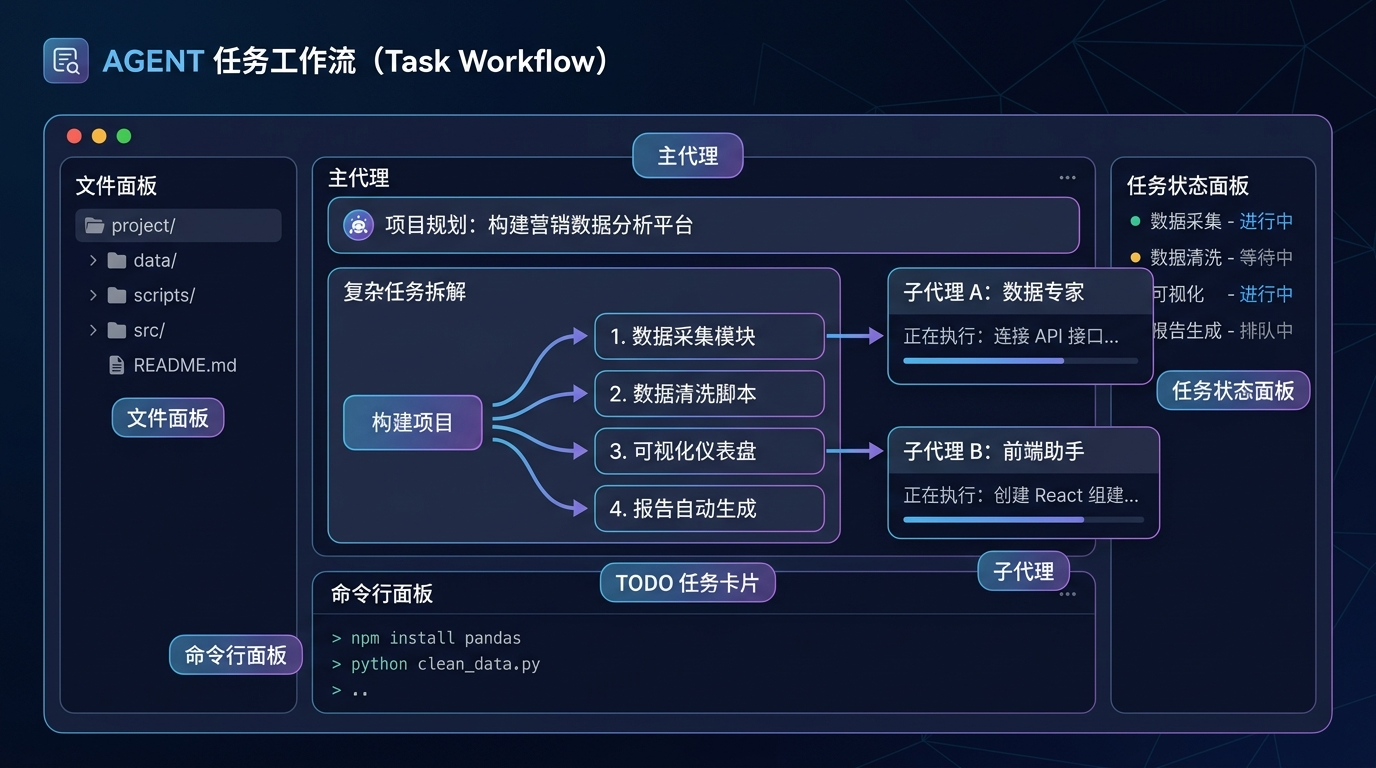
复杂任务最怕没有结构。Deep Agents 的做法,是把计划、分工和执行状态都放进同一条工作流里。
一旦任务变长,就很容易出现几个问题:
- 没有明确计划,做到一半就飘了
- 中间状态全靠上下文记,越聊越乱
- 需要读文件、改文件、再继续决策时断层
- 子任务想拆出去做,但上下文容易互相污染
Deep Agents 的价值就在这里:它不赌模型自己突然学会“复杂度管理”,而是把这些能力直接做成默认件。
一句话概括:它卖的不是更强的回答,而是更稳的任务组织能力。
最短上手闭环
跑 SDK
先装包:
最小示例:
这段代码的重点不是“又一个聊天接口”,而是你已经拿到一套默认带 planning、文件和子任务机制的 agent 骨架。
看 CLI
如果你更关心“能不能直接拿来当终端 agent 用”,CLI 其实更值得看。
启动后直接用:
CLI 在 SDK 之上又补了几层产品能力:
- 交互式 TUI
- 会话恢复
- Web search
- 远程 sandbox
- 持久记忆
- 自定义 skills
- 非交互 headless 模式
- human-in-the-loop 审批
SDK 更像底座,CLI 更像已经能直接上手的终端产品。
我觉得它最值得看的 3 个点
1. 把 planning 变成默认能力
很多 agent 不是真的不会做,而是真的不会拆。
Deep Agents 直接把 write_todos 放进默认工具里,这比一句“think step by step”实在得多。
任务一旦超过单轮问答,计划就不该藏在 prompt 里,而应该变成一个能持续更新的工作状态。
2. 把文件系统当工作记忆
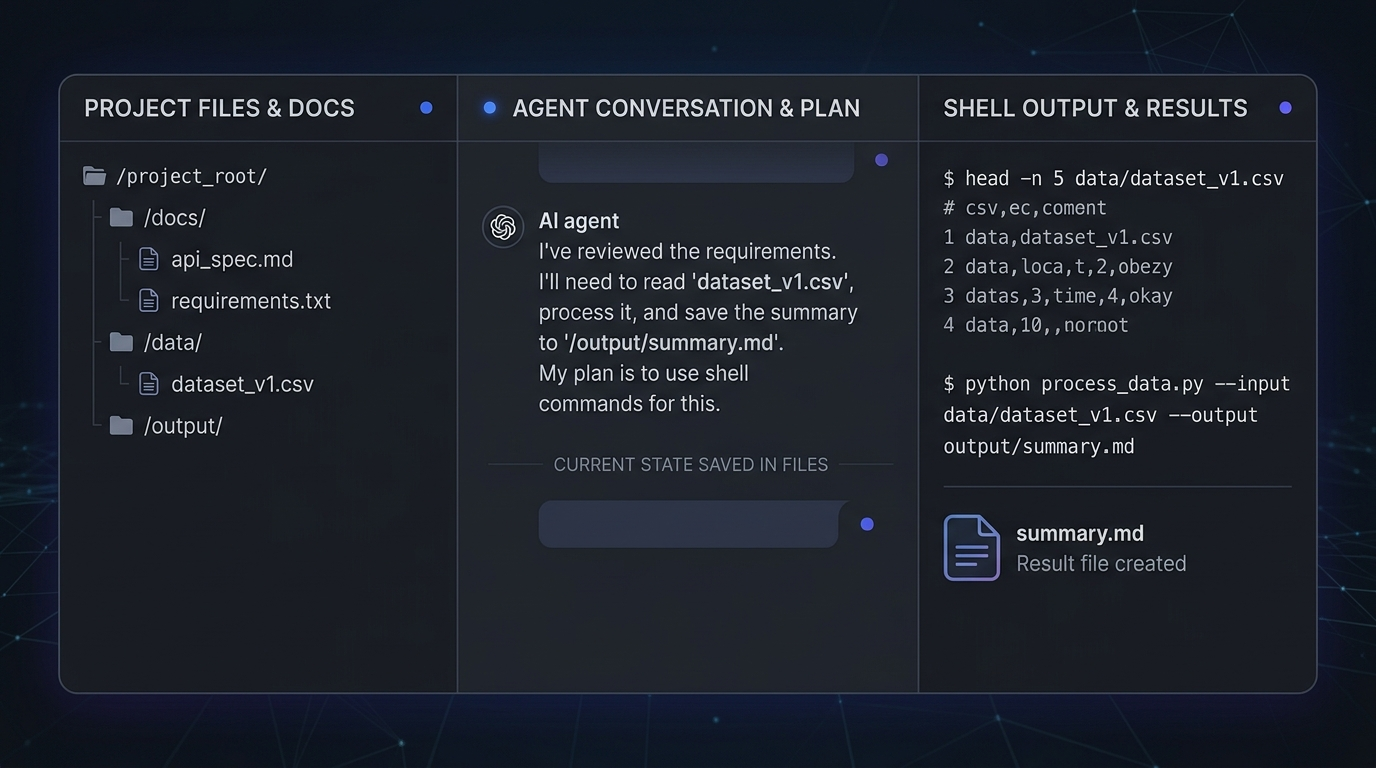
比起把所有状态都塞进上下文,把中间结果写回文件,通常更接近真实可复用的工作方式。
这一点很关键。
很多 agent 本质上还是靠上下文硬撑,任务一长就开始丢状态。
Deep Agents 的做法更工程化:该读文件就读文件,该写结果就写结果,输出太长就落盘,对话太长就摘要。
把状态留在文件里,通常比把状态全塞进上下文里靠谱。
3. Sub-agent 不是高级玩法,而是标配
README 里把 task 明确列成默认能力,这个信号很强。
它不是在说“你也可以试试多 agent”,而是在说:复杂任务本来就应该允许分工,所以 sub-agent 应该是默认组件。
这点在 deep_research 示例里尤其明显:先保存请求,再列 TODO,再把子问题拆给 sub-agents,最后回主代理收束。
这已经很接近真实工作流了。
适合谁,不适合谁
适合
- 已经不满足于做简单 tool-calling demo 的人
- 想做 research agent、coding agent、content agent 的人
- 想要一套现成骨架,而不是每次自己拼状态管理的人
- 本来就在 LangChain / LangGraph 生态里的人
不太适合
- 只想接一个很轻的聊天机器人
- 任务里基本不涉及文件、计划、子任务拆分
- 不想接受它这套偏“工程化”的默认做法
如果你的任务很轻,它可能偏重;但如果你的任务本来就复杂,它反而更对路。
上手前先记住 3 个点
- 它不是更花哨的 prompt,而是一套更重的运行时
- 它遵循的是
trust the LLM思路,边界更多靠工具层和 sandbox 控制 - 更新节奏很快,适合先固定版本再用,不建议直接长期追 main
最后一句判断
如果只看一句话,我对 Deep Agents 的判断是:
它值得看的地方,不是又造了一个 agent,而是先把复杂任务 agent 的工作台标准化了。
接下来很多 agent 产品比拼的,未必只是模型,而是谁更会组织任务、状态、工具、子代理和工作区。
Deep Agents 至少已经把这件事认真做成产品形态了。
如果这篇对你有用,建议点个关注。我会持续把 GitHub 上值得用的 AI 工具拆成「最短上手闭环 + 坑点清单 + 可复用配置」,让你少走弯路。
关注微信公众号
想第一时间看到后续的工具拆解与实战更新,欢迎扫码关注公众号。
