3.6万星,claude-mem 给 Claude Code 补上了“长期记忆”
- Prompt / Skills / 配置
- 2026-03-17
- 28热度
- 0评论
项目卡片 - 项目名:claude-mem - GitHub:https://github.com/thedotmack/claude-mem - 热度信号:36,732 Stars / 2,639 Forks / 近一周仍在连续发版 - 一句话判断:它不是“帮你保存聊天记录”,而是想让 Claude Code 在新 session 里还能接着上次的活继续干。
如果你经常用 Claude Code 写代码,应该都遇到过这种情况:
昨天刚把项目结构、改动原因、踩过的坑都讲清楚,今天重开一个 session,它又像失忆了一样,你只能从头再讲一遍。
claude-mem 要补的,就是这段断掉的连续性。
它不是把整段旧对话重新塞回上下文,而是把过去的工具调用、关键观察、阶段总结压成一层可检索、可分层展开的工作记忆。下一次新会话开始,Claude 先看到的是历史索引,再按需要回拉细节,而不是一上来就把旧上下文整段吞进去。
所以这个仓库真正有意思的地方,不是“到底记住了多少”,而是:怎么在 token 预算有限的前提下,让过去做过的事继续有用。

图:它更像是在给 Claude Code 补一层跨 session 的工作记忆,而不是简单保存聊天记录。
它到底在做什么
你可以把 claude-mem 理解成 4 层:
1. hooks 负责记录发生了什么。 Claude Code 在 SessionStart、UserPromptSubmit、PostToolUse、Stop 这些生命周期触发 hooks,把会话里的关键动作记下来。
2. worker service 负责整理和对外服务。 本地会起一个常驻服务,默认跑在 37777 端口,接收 observation、生成 summary、提供查询接口,还带一个 Web Viewer。
3. SQLite / Chroma 负责存储和检索。 会话、observation、summary 会先落到 SQLite;如果开了 Chroma,再补一层语义检索。
4. retrieval 负责把历史按需拿回来。 它不是简单“全部回放”,而是走 search → timeline → get_observations 这条路:先看索引,再看时间线,再拿细节。
这套设计其实很对症: AI 编程里真正贵的,不是模型记不住,而是每次都要把旧记忆整段重读一遍。
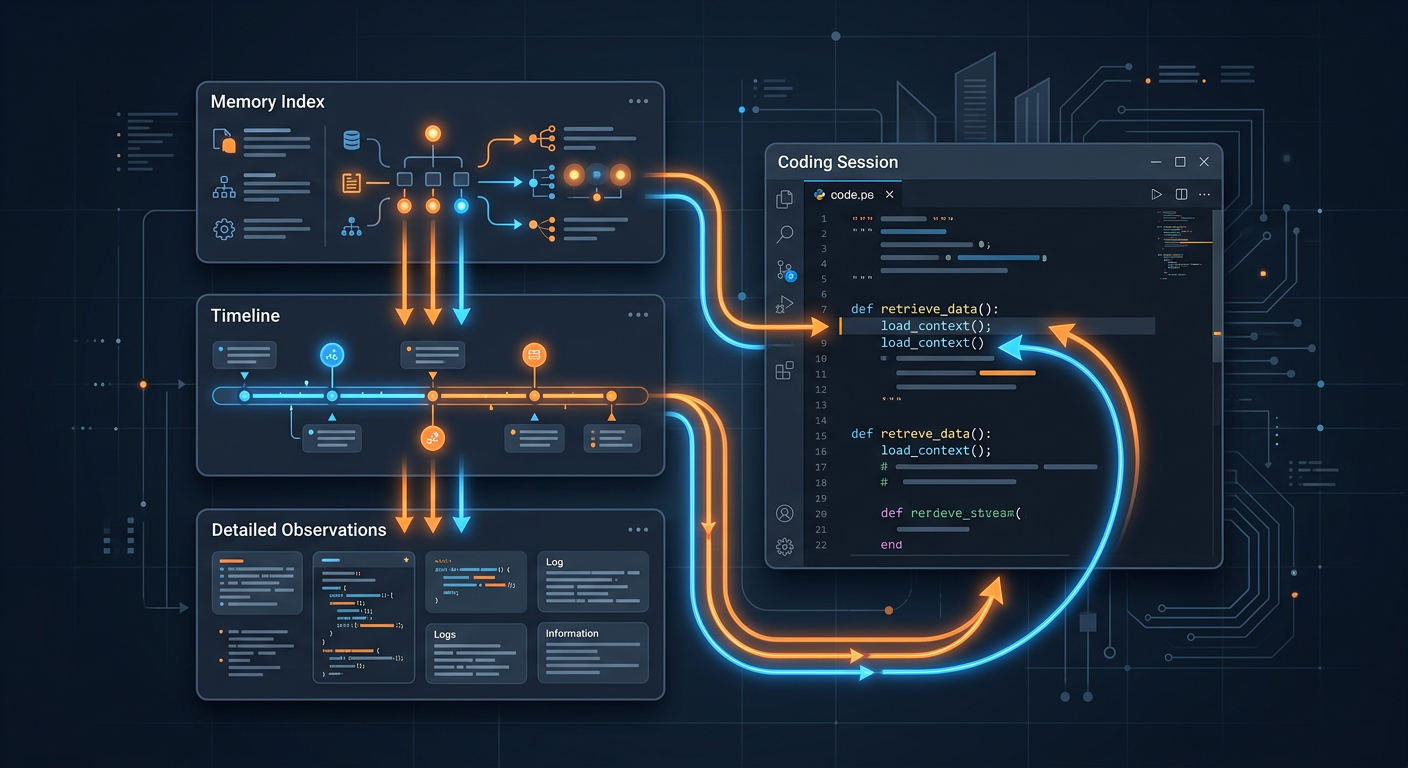
图:先索引、再时间线、再细节,是 claude-mem 这套记忆方法里最关键的一步。
为什么这个仓库这波会火
因为它解决的不是一个小痛点,而是 Claude Code 真正走向日常开发后,大家都会遇到的那个问题:
会话会断,记忆会丢,第二天很难接着干。
而 claude-mem 给出的方案,不是继续堆上下文窗口,而是换一种思路:
- 先把历史压成 observation 和 summary
- 再把历史做成可检索索引
- 真要用的时候按层取回,而不是整段灌回去
这也是为什么它现在已经不太像一个“小插件”了,更像一层围绕 AI 编程工作流搭出来的记忆基础设施。
主线能力已经很完整:
- Claude Code 插件市场可直接安装
- 本地 Web Viewer 可以看记忆流
- MCP 工具可以查历史
- 有模式系统,可以切不同工作模式和语言
- 配置里还能切 Claude、Gemini、OpenRouter 等 provider
而且它已经不只盯着 Claude Code:
- 仓库里有 Cursor hooks 集成
- 也有 OpenClaw 集成,能把 agent observation 同步到
MEMORY.md
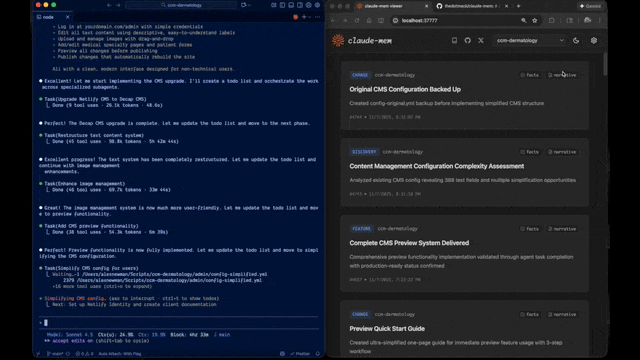
图:仓库里已经有可直接观看记忆流的界面,这也是它不像“小插件”的地方。
这说明作者想做的,已经不是“让一个聊天窗口更聪明”,而是把 AI agent 的长期上下文管理 做成一层可迁移的通用能力。
它适合谁装
我觉得最适合 3 类人:
1. 长期维护同一代码库的人。 项目越复杂、上下文越多,它越值钱。
2. 经常被打断、需要隔天续写的人。 今天修一半 bug,明天继续;白天让 AI 改代码,晚上再回来查原因,这类场景特别吃跨 session 连续性。
3. 已经开始多入口协作的人。 你在 Claude Code 里写、在 Cursor 里看、在 OpenClaw 里跑 agent,这时候“统一记忆层”会比单个聊天窗口重要得多。
反过来,如果你只是偶尔让 AI 写个一次性脚本,那它可能会显得偏重。因为 claude-mem 背后不是一个纯前端小玩具,而是一整套 hooks、worker、配置文件和本地存储机制。
上手前先知道两个坑点
第一,正确安装姿势是走插件市场,不是 npm install -g。 仓库文档写得很明确:全局 npm 安装拿到的更像 SDK,本身不会自动把 hooks 和 worker 配好。
第二,它不是“装完就完事”的傻瓜记忆。 它的价值很大一部分来自它那套上下文方法论:先索引,再展开,按需读取。 你越接受这套思路,它越有用;如果你期待的是“全部自动记住并自动塞回去”,那你反而会觉得它不够爽。
我的判断
如果只用一句话总结这个仓库,我会这么说:
claude-mem 不是让 Claude Code 变得“更能记”,而是让它终于有机会像个能连续推进工作的搭子。
它真正值钱的地方,不在“记住全部”,而在于把过去做过的事整理成下一次还能继续利用的信息。
这也是它能涨到 3.6 万多星的原因:大家真正缺的,从来不是再多一个模型入口,而是一个能让 AI 到了第二天还知道自己上次干到哪的记忆层。
如果你已经把 Claude Code 当成日常开发工具,这个项目值得亲自装一遍、跑几天,再决定要不要把它留进自己的默认工作流。
如果这篇对你有用,建议点个关注。我会持续把 GitHub 上值得用的 AI 工具拆成「最短上手闭环 + 坑点清单 + 可复用配置」,让你少走弯路。
关注微信公众号
想第一时间看到后续的工具拆解与实战更新,欢迎扫码关注公众号。
