15.7k 星,GitNexus 想解决的不是 AI 写代码,而是 AI 看不懂代码
- AI 工具拆解
- 2026-03-17
- 42热度
- 0评论
摘要: 很多 AI 编程翻车,不是因为模型不够强,而是它压根没看懂这次改动会牵动谁。GitNexus 想补的也不是“更会写代码”,而是“代码结构感”——先把影响范围、调用链、依赖关系摊开,再让 AI 动手。这也是它最近火起来真正值得看的地方。
项目卡片
- 项目名: GitNexus
- GitHub: https://github.com/abhigyanpatwari/GitNexus
- 热度信号: 15.7k+ Stars,1.8k+ Forks(2026-03-17)
- 一句话判断: 这不是帮 AI 多写代码的工具,而是帮它在动手之前,先看清这次改动会牵动谁。
现在很多 AI 编程工具最大的问题,已经不是“会不会写代码”,而是“知不知道自己改了什么”。
GitNexus 这波火起来,抓住的也是这个点。
它不是在教 AI 多写一点代码,而是在给 AI 编程工具补一层“架构感知能力”。 它先把代码仓库索引成知识图谱,把函数、类、接口、文件、模块、执行流程之间的关系算出来,再通过 MCP 工具暴露给 Cursor、Claude Code、OpenCode、Codex 这类 agent。
它要补的,其实就是一句话:
AI 能写局部代码,但在真实项目里,经常不知道“这行改动会影响谁”。
README 里举的例子就很典型:AI 改了 UserService.validate(),却不知道后面还有几十个函数依赖这个返回结果。于是改动也许能过眼前任务,但会把真实调用链一起带崩。
GitNexus 想做的,就是把这种“改完才知道出事”的代价,提前变成可查询、可验证的结构信息。
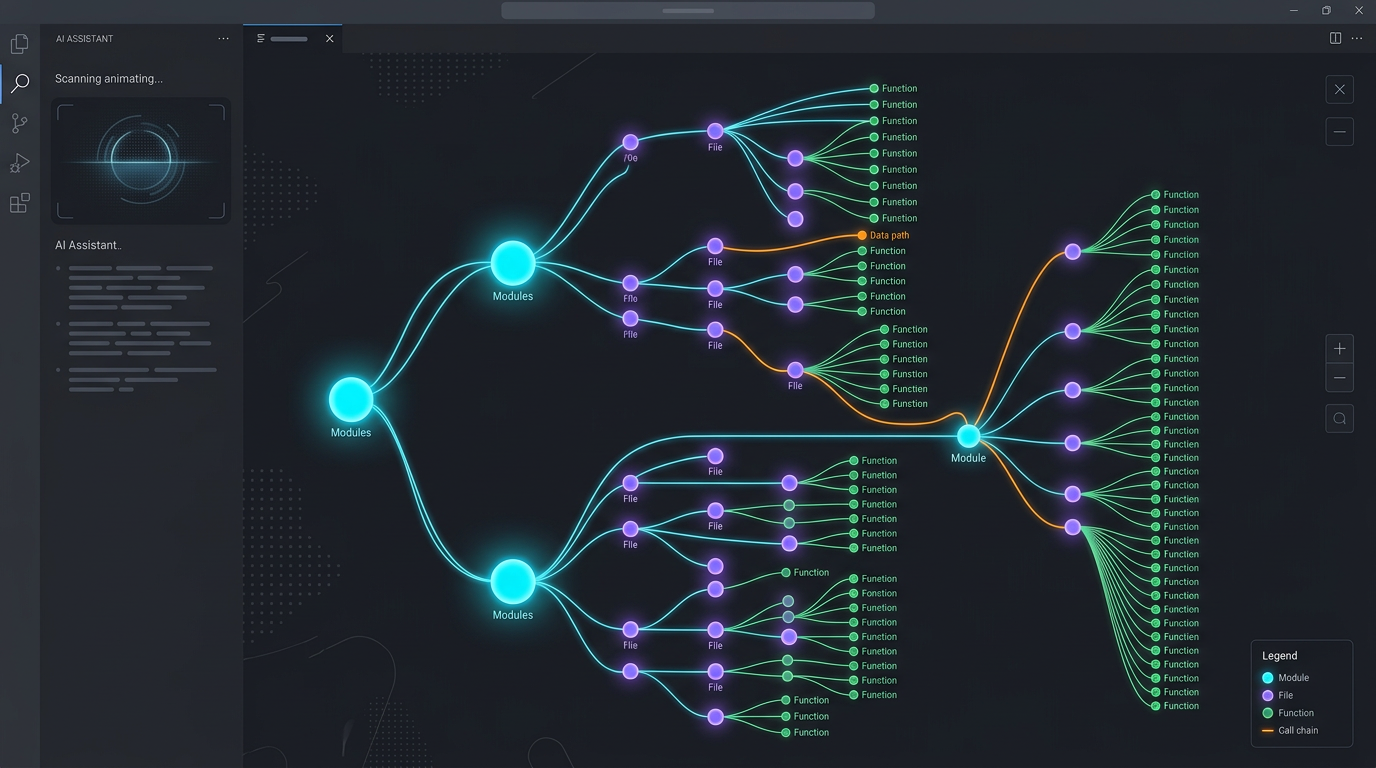
图:先把仓库里的函数、模块、调用链和依赖关系摊开,AI 才更像是真的在“理解代码”,而不是只在“补代码”。
它到底强在哪
这个项目最有意思的地方,不是“能画图”,而是把很多本来要靠模型自己慢慢搜、慢慢猜的事情,提前在索引阶段算好了。
它大概在做这几件事:
- 扫描仓库结构,抽取函数、类、方法、接口
- 解析 import、调用关系、继承关系
- 把相关符号聚成 functional communities
- 从入口点往下追 execution flows
- 最后把这些结果交给 MCP 工具查询
所以它给 agent 的,不是一堆生的关系边,而是更接近“已经整理过的上下文”。
仓库里现在暴露的核心 MCP 工具有 7 个,最实用的是这几个:
query:按概念查执行流,不只是搜文件名context:看某个符号的 360 度上下游关系impact:改一个函数前,先看 blast radiusdetect_changes:把 git diff 映射到受影响流程rename:做跨文件 rename,而不是盲搜替换
这意味着它最适合的使用场景,不是“我想让 AI 多写一点代码”,而是:
我已经让 AI 参与开发了,但我不想每次都赌它有没有漏掉关键依赖。
为什么这类工具现在开始变重要
过去一段时间,AI 编程产品都在拼模型、拼交互、拼自动执行。但真到了中大型仓库,瓶颈常常不在“会不会写”,而在“知不知道自己在动什么”。
GitNexus 的思路其实很朴素,也很工程化:
- 模型还是那个模型
- 编辑器还是那个编辑器
- 但在它真正动手之前,先给它一份更像“架构地图”的上下文
README 里甚至直接把自己和 DeepWiki 做了区分:DeepWiki 更偏“帮助理解代码”,GitNexus 更偏“帮助分析代码”。这个定位我觉得是准的。
因为在实际开发里,理解代码只是第一步;改代码之前,知道影响范围,才是真正决定稳定性的那一步。
一个最短上手闭环
如果你想判断它值不值得装,不用先啃完整套概念,直接走这一圈就够了。
第一步,在仓库根目录执行:
这个命令做的事很实在:建立本地索引、生成 AI 上下文文件、安装技能文件,并给 Claude Code 这类工具接上更深一层的工作流。
第二步,执行一次:
它会尝试给 Cursor、Claude Code、OpenCode 等工具写全局 MCP 配置。仓库里的 setup.ts 也能看出来,这个项目不是只做“协议兼容”,而是很认真地在做编辑器接入层。
第三步,日常使用时,把它当成 AI 编程前的“结构探测器”:
- 想理解某块逻辑:先
query - 想改某个核心函数:先
impact - 准备提交:跑
detect_changes
如果你已经习惯让 Claude Code 或 Cursor 直接改代码,这一步体验会很明显:它不是让 agent 更能说,而是让 agent 更少漏。
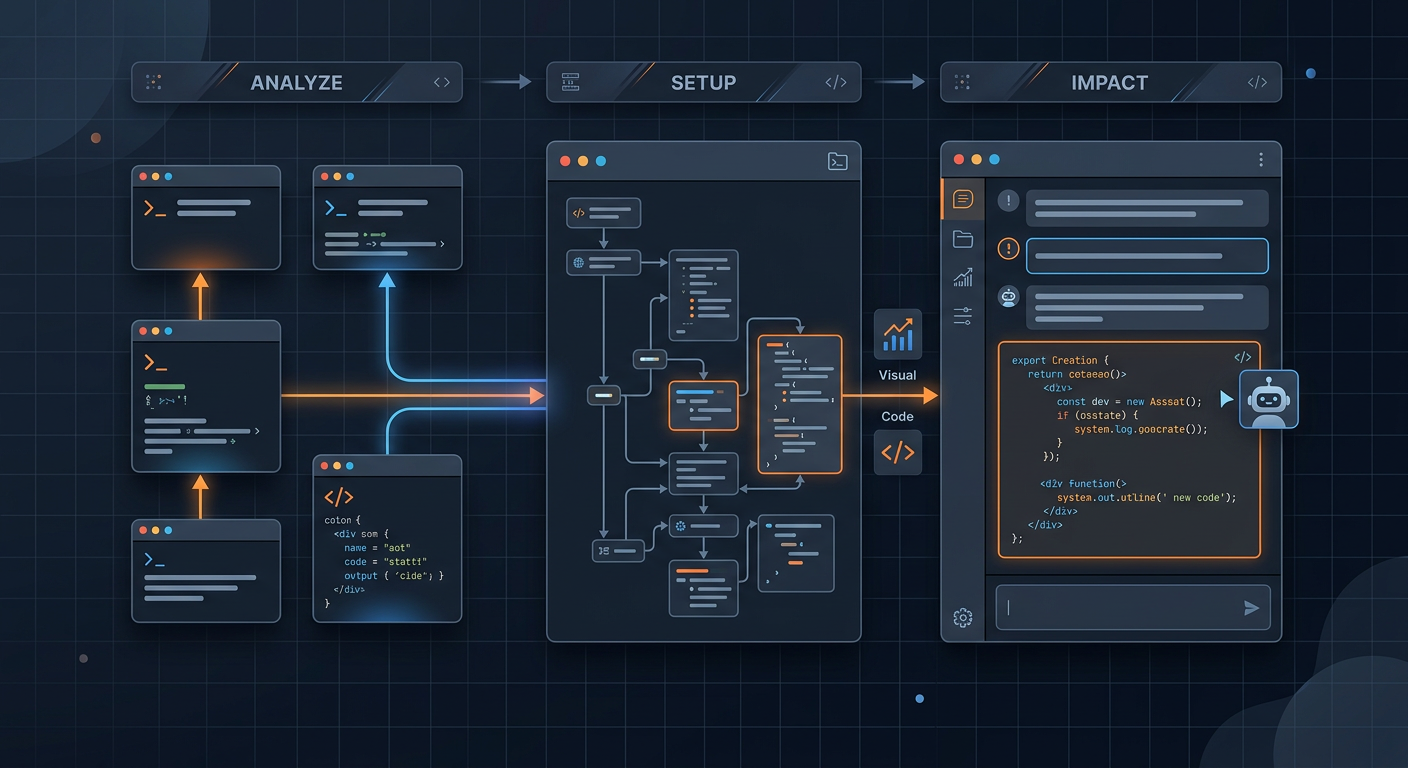
图:如果只记一个最短闭环,差不多就是 analyze 建索引、setup 接入工具、impact 再决定要不要动手改。
这个项目为什么会火
我觉得不只是因为它做了 MCP。
更核心的原因是,它抓住了一个非常真实的痛点:AI 编程的失败,很多不是生成失败,而是上下文失败。
而且 GitNexus 没停在概念层。你能看到它把产品分成了两条线:
- CLI + MCP:适合日常开发,把本地仓库长期索引起来
- Web UI:适合快速浏览、演示、一次性分析
甚至它还做了 serve 模式,让本地索引结果直接桥接到网页前端,不用重新上传仓库。这种设计说明团队已经在认真处理“真实工作流”,不是只做一个能演示的 demo。
也要提前知道的几件事
如果你准备试,我觉得有三点最好先有预期。
第一,它更适合真实代码库,不是玩具项目。仓库里对 Web UI 也写得很明确:纯浏览器模式会受内存限制,较大的仓库更适合走本地 backend。
第二,它的优势不在“替代模型”,而在“放大模型”。README 里有一句话挺关键:连更小的模型也能因为拿到完整架构上下文,而表现得更像大模型。这条路线很值得继续看。
第三,它当前许可证是 PolyForm Noncommercial。如果你是个人研究、学习、内部试用问题不大,但商业团队真要正式引入,最好先把授权边界确认清楚。
最后一句
如果你把 GitNexus 当成又一个“AI 编程工具榜单里的新名字”,它会显得有点复杂。
但如果你把它看成给 agent 加的一层“代码关系基础设施”,一下就好理解了:
它不负责替你做决定,它负责让 AI 在做决定之前,先少漏、少误伤。
这也是我觉得它值得关注的原因。
如果这篇对你有用,建议点个关注。我会持续把 GitHub 上值得用的 AI 工具拆成「最短上手闭环 + 坑点清单 + 可复用配置」,让你少走弯路。
关注微信公众号
想第一时间看到后续的工具拆解与实战更新,欢迎扫码关注公众号。
