4 天涨星 1741,pi-autoresearch:把“让 AI 自己做性能实验”这件事做成了可复盘闭环
- 工作流与自动化
- 2026-03-16
- 52热度
- 0评论
4 天涨星 1741,pi-autoresearch:把“让 AI 自己做性能实验”这件事做成了可复盘闭环
如果你最近已经在用 AI 改代码,八成也碰到过一个问题:模型会提优化,但很难持续、机械、老老实实地做几十轮“改一点、跑一次、保留有效结果”。
pi-autoresearch 值得看的地方,就在这里:它不是教 AI 更会想,而是把实验循环产品化了。
项目卡片
- 项目名:pi-autoresearch
- GitHub:https://github.com/davebcn87/pi-autoresearch
- 涨星速度:仓库 2026-03-11 创建,到我写这篇时约 4 天拿下 1741 Star
- 一句话判断:最有意思的不是“AI 会优化”,而是“AI 终于有了一套靠流水线反复做实验的办法”。
它到底解决了什么问题
很多 AI 编程演示,强在“想法很多”,弱在“实验纪律差”。
今天试了什么、为什么回滚、最优结果是哪一版,往往全靠聊天记录和人脑补。一旦实验轮数多起来,这种方式基本必乱。
pi-autoresearch 的切法很直接:
- 扩展层提供
init_experiment、run_experiment、log_experiment - 技能层生成
autoresearch.md、autoresearch.sh - 持久化层把每次实验写进
autoresearch.jsonl
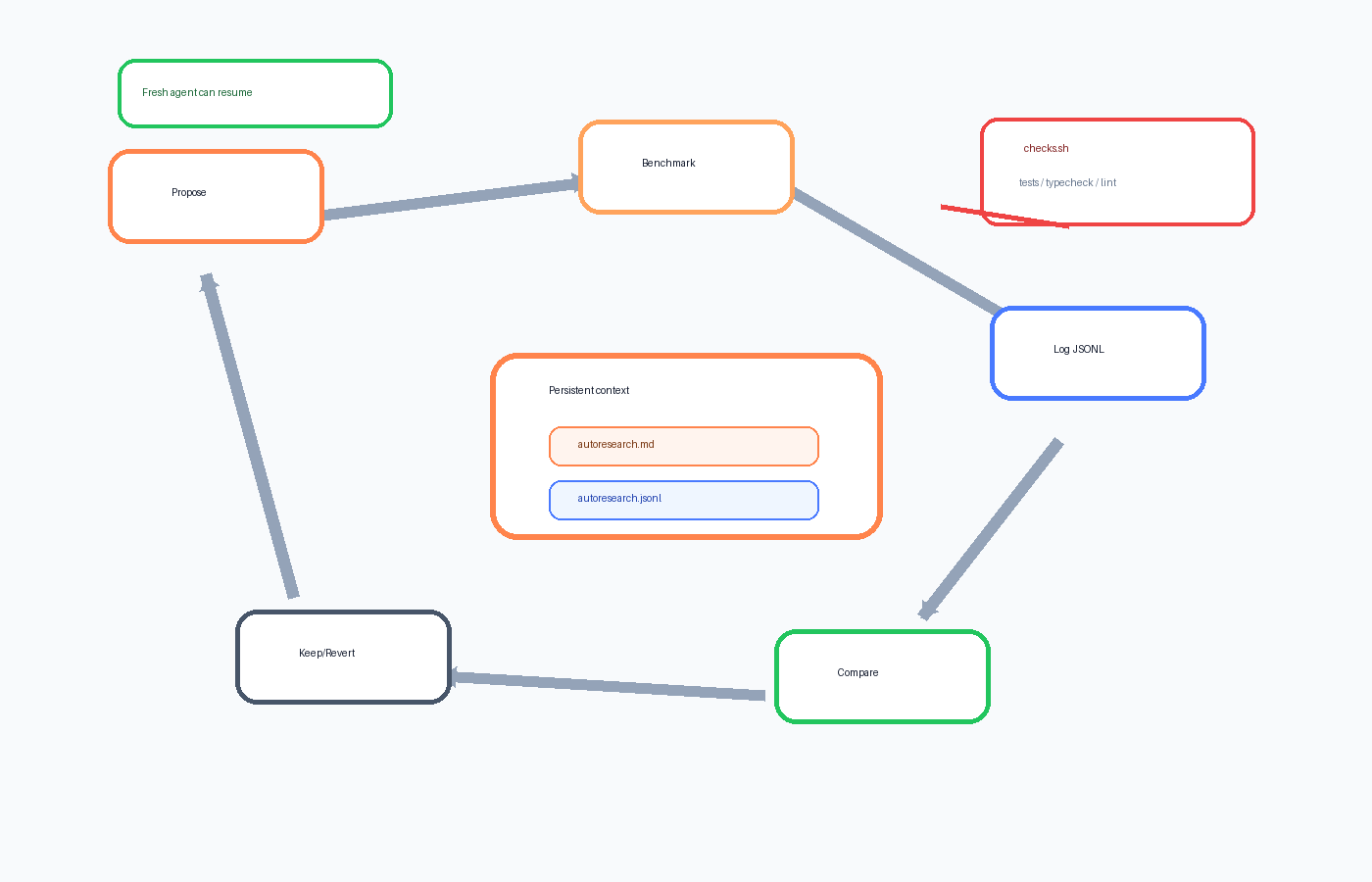
扫这张图就够了:pi-autoresearch 不是替你拍脑袋想优化,而是把“提出改动 → 跑基准 → 记结果 → 保留或回滚 → 继续下一轮”钉成了固定回路。真正值钱的是可重复,不是灵感。
那个“自动试验 → 评分/记录 → 保留有效改动”的闭环,到底怎么跑
README 把主循环写得很直白:edit → commit → run_experiment → log_experiment → keep or revert → repeat。
落到代码里,大概是这么一套节奏:
- 先用
autoresearch-create收集目标、命令、主指标、可修改范围。 - 技能在项目里写出
autoresearch.md、autoresearch.sh,必要时再补autoresearch.checks.sh。 init_experiment把本轮配置写进autoresearch.jsonl,先立实验表头。- agent 改代码后,
run_experiment执行命令,计时、抓输出、判断 benchmark 有没有跑通。 - 如果存在
autoresearch.checks.sh,benchmark 通过后还会再跑测试、类型检查、lint 这类“回压检查”。 log_experiment记录这轮结果:指标值、状态、描述、commit、附加指标,逐行追加进autoresearch.jsonl。- 只有主指标真的变好,而且 checks 没挂,结果才会被标成
keep并自动 commit;否则就是discard、crash或checks_failed,改动回滚,继续下一轮。
关键在于:它不是让 agent“感觉这次不错就留下”,而是把“留不留”收紧成了有门槛的决策。
比如仓库新加的 autoresearch.checks.sh 就很像工程里的刹车系统:benchmark 也许变快了,但如果测试没过、类型炸了,这轮结果只能记成 checks_failed。
它和普通“让 agent 自己改代码”相比,多了什么工程味
我觉得核心不是“会自动跑”,而是多了三层约束。
第一层,是把目标压成单一指标。 它要求你明确 metric 名称、单位、方向。没有这一步,agent 很容易在“代码更优雅”“逻辑更聪明”“也许更快”之间飘来飘去。
第二层,是把每轮实验都变成可追账的记录。 autoresearch.jsonl 是追加式日志;autoresearch.md 像实验笔记,写清目标、范围、已试思路和结论。新 agent 接手,只要读这两个文件就能续跑。
第三层,是把保留改动做成硬规则。 keep 才自动 commit,discard/crash/checks_failed 就回退。普通 agent 改代码更像“写完再看”;pi-autoresearch 更像“每轮先过闸机,再决定能不能进主线”。
仓库里已经给出的可落地用法,其实很清楚
如果你已经在用 Pi,上手路径并不长:
pi install https://github.com/davebcn87/pi-autoresearch
然后在目标项目里执行:
/skill:autoresearch-create
它会问四类信息:
- 你想优化什么
- 具体跑哪条命令
- 主指标是什么,方向如何
- 哪些文件能改,哪些别碰
跑起来后,项目目录里主要会出现这几样东西:
autoresearch.md:实验说明书,也是续跑上下文autoresearch.sh:真正执行 benchmark 的脚本,约定输出METRIC name=numberautoresearch.checks.sh:可选的正确性检查脚本autoresearch.jsonl:每轮实验结果日志
这个目录结构很朴素,但很实用。状态没有锁死在会话里,而是尽量落回普通文件。 所以你可以停、可以看、可以换 agent。
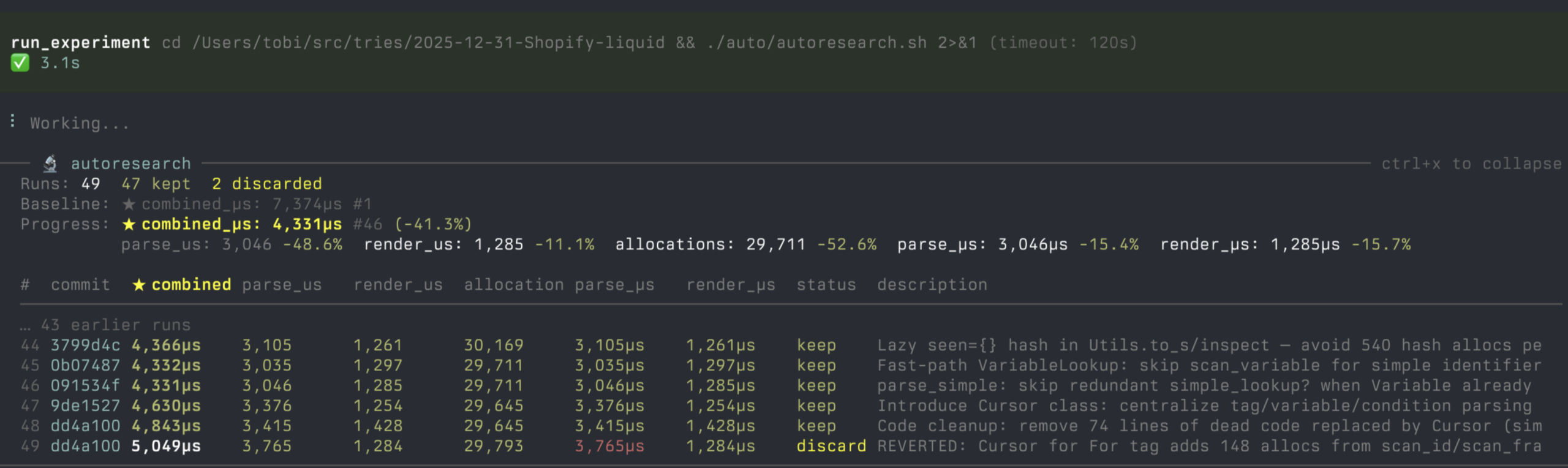
看这张图基本就明白了:上面先给你 runs、best、keep / discard / crash / checks failed;下面再把每轮 commit、指标、状态、描述摊开。AI 有没有在认真做实验,不用猜,面板里一眼就能看出来。
另外,作者最近两次更新也很说明问题:一是补了 autoresearch.checks.sh,二是补了 auto-resume guard,避免用户手动停下后又被无脑续跑。
谁会真用到它,谁可能暂时用不上
会真用到它的人:
- 已经有稳定 benchmark 的工程师
- 想系统压测试耗时、构建时间、包体积、训练指标的人
- 希望让 AI 连续跑几十轮小实验,而不是只给几条建议的人
- 需要把优化过程留痕,方便复盘或交接的人
可能暂时用不上的人:
- 你的任务没有可量化指标,只能凭主观判断
- 目标是视觉体验、产品感觉、交互审美,这类很难脚本化评分
- 团队还不接受 agent 自动改文件、跑命令、自动 commit
- 你当前只想要“一次性建议”,并不想维护持续实验回路
一句话说,它更适合“优化流程已经存在,但执行太累”的团队,不太适合“问题都还没定义清楚”的阶段。
用之前记住 3 个点
第一,主指标一定要硬。 没有稳定 metric,循环只会变成随机游走。
第二,autoresearch.sh 要尽量快。 每多 1 秒,乘上几十上百轮,就是很真实的成本。
第三,能加 checks 就尽量加。 不然你得到的很可能只是“更快地把东西改坏了”。
最后一句判断
如果你对 Agent 编程真正感兴趣,pi-autoresearch 是个很值得拆的仓库。它没有把重点放在花哨交互,而是把最枯燥、也最难坚持的实验闭环补齐了。
现在它还很早期:仓库刚创建不久,暂无正式 release,代码体量也不大。但也正因为早,你反而更能看清这条产品思路:先把自动实验做扎实,再谈更大的自动编程。
如果这篇对你有用,建议点个关注。我会持续把 GitHub 上值得用的 AI 工具拆成「最短上手闭环 + 坑点清单 + 可复用配置」,让你少走弯路。