24 小时涨星 1400+,OpenViking 不只是 Memory,它在重做 Agent 的上下文底座
- 工作流与自动化
- 2026-03-15
- 28热度
- 0评论
项目卡片
- 项目名:OpenViking
- GitHub:https://github.com/volcengine/OpenViking
- 涨星速度:近 24 小时约 +1400 Star(写稿时总 Star 约 1.06 万)
- 一句话判断:它不是想给 Agent 再补一个 memory 功能,而是想把上下文这层底座重新搭起来。
很多 Agent 一开始都挺聪明,越跑越乱。不是模型突然变笨,而是上下文开始失控:文档在 RAG 里,偏好在 memory 里,技能说明又是一套 prompt。每轮都能拿到一点信息,但很难知道该先看什么、出了错去哪里查。
OpenViking 想解决的,就是这层麻烦。它不是再给 Agent 加一个“记住昵称和偏好”的小抽屉,而是把上下文当成一套数据系统来管。

图:项目官方 banner。重点不是“更强 memory”,而是 Context Database。
1)它到底把什么重新组织了?
OpenViking 的核心动作,是把 resource、memory、skill 都统一抽象成 Context,放进同一个 viking:// 命名空间里管理。
翻成人话,这意味着:以前 Agent 要分别去找“资料库、记忆库、技能说明”,现在它面对的是同一棵上下文目录树。访问方式也更像文件系统:ls / tree / find / read / overview / abstract。
它解决的,不只是“接口统一”,而是一个更现实的问题:上下文终于能按同一种方式被查找、回看和调试。
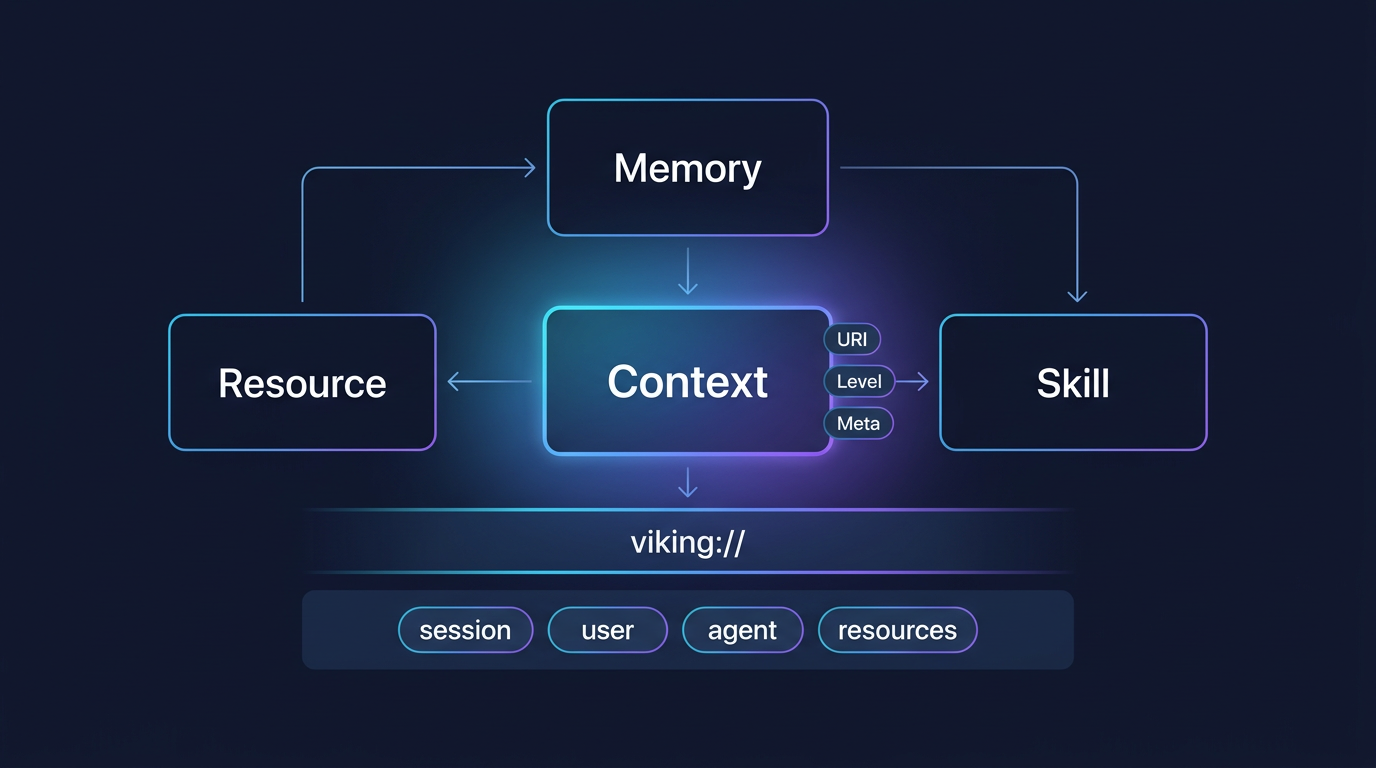
图:OpenViking 真正统一的,不是几个零散模块,而是 resource、memory、skill 这三类上下文本身。它们进了同一套 Context 模型和 viking:// 目录后,Agent 才第一次能像查文件系统一样统一查、统一读、统一排错。
仓库里的预设目录也很直观:
viking://resources/放共享资料viking://user/.../memories/放用户长期记忆viking://agent/.../memories/放 Agent 学到的 caseviking://agent/.../skills/放技能定义viking://session/...放单次会话及归档
所以它更像“Agent 的上下文文件系统 + 索引层”,而不是再挂一个 memory 插件。
2)为什么说它不是普通 memory?
普通 memory 解决的是“记住一点东西”。比如用户喜欢什么、上次聊到哪里、某个偏好要不要延续。
但 Agent 真正难的,通常不是“有没有记住”,而是:
- 文档、案例、技能、历史决策混在一起时,怎么组织?
- 一次任务里,哪些上下文该先给模型,哪些先别给?
- 出错时,能不能追溯这段回答到底吃进了哪些上下文?
旧办法当然也能拼起来:FAQ 用 RAG,用户资料塞 memory,技能写进 system prompt。问题是,一旦任务变长、会话变多,这套拼装法就越来越像临时搭线:能跑,但很难控成本,也很难调。
OpenViking 补的是这块空白。它不是只记“事实”,而是把可供 Agent 使用的一整套上下文对象统一管理。所以我更愿意把它看成 Agent 的上下文底座。
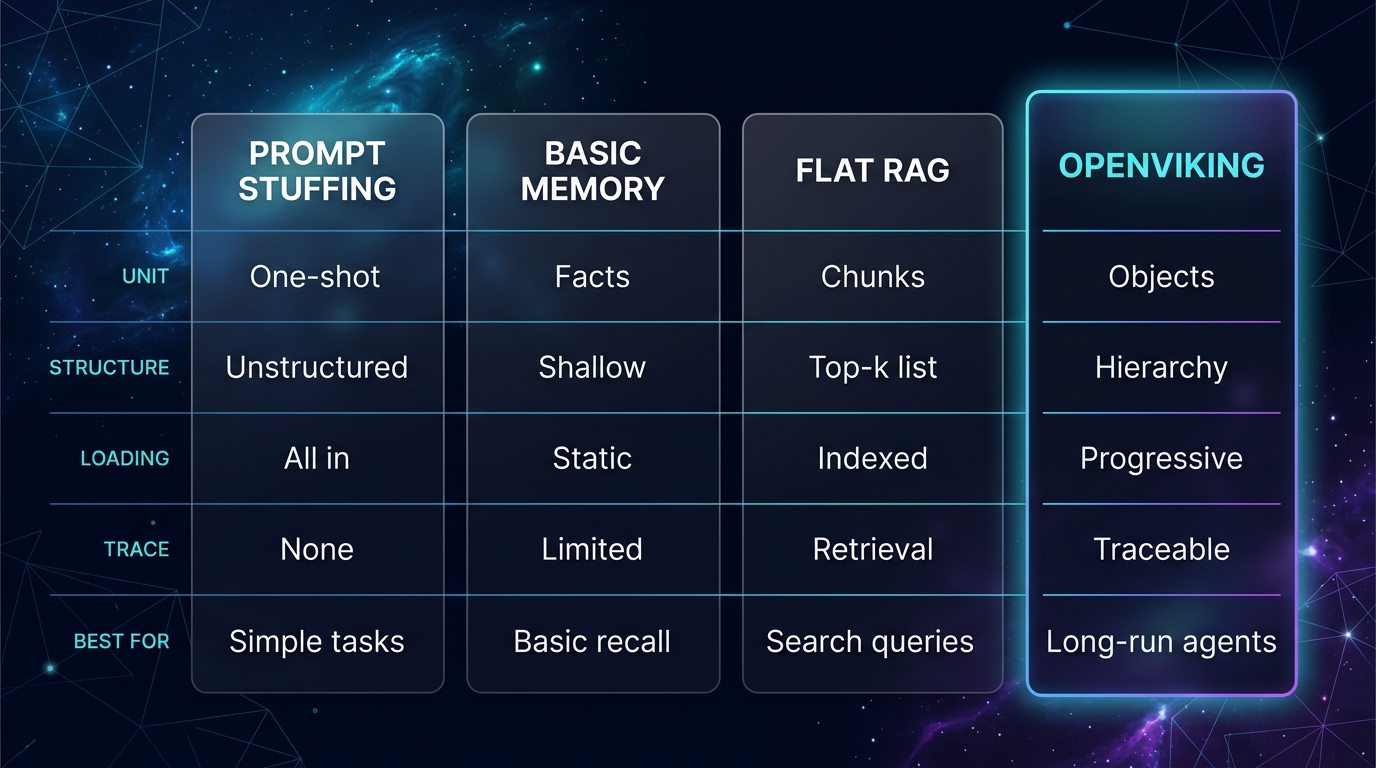
图:它和普通 memory / RAG 的差别,不是“多一个检索层”这么简单。普通方案更像把信息拼起来临时用,OpenViking 则把上下文的组织方式、层级关系和装载顺序一起定义了,所以更像底座,不像补丁。
3)L0 / L1 / L2 为什么不只是摘要层级?
这部分最容易被误解成“哦,就是三层摘要”。其实没那么简单。
OpenViking 给每个节点准备了三层内容:
- L0:
.abstract.md,大约 100 tokens,用来先判断“值不值得继续看” - L1:
.overview.md,大约 1k~2k tokens,用来理解结构、边界和导航关系 - L2:原始内容,只在真的需要细节时再读
如果只把它理解成“摘要、长摘要、全文”,会低估它的价值。因为它实际影响的是两件事:
第一,上下文成本怎么花。不是每次都把全文塞进窗口,而是先用便宜的 L0/L1 做判断,只把真正需要的 L2 拉进来。
第二,调试方式怎么变。以前很多 Agent 出错,你只能看到“最后喂给模型的 chunk”。现在更容易追踪:它是在哪个目录被召回的,先看了哪个 L0/L1,为什么继续下钻到 L2。也就是说,可观察性更强。
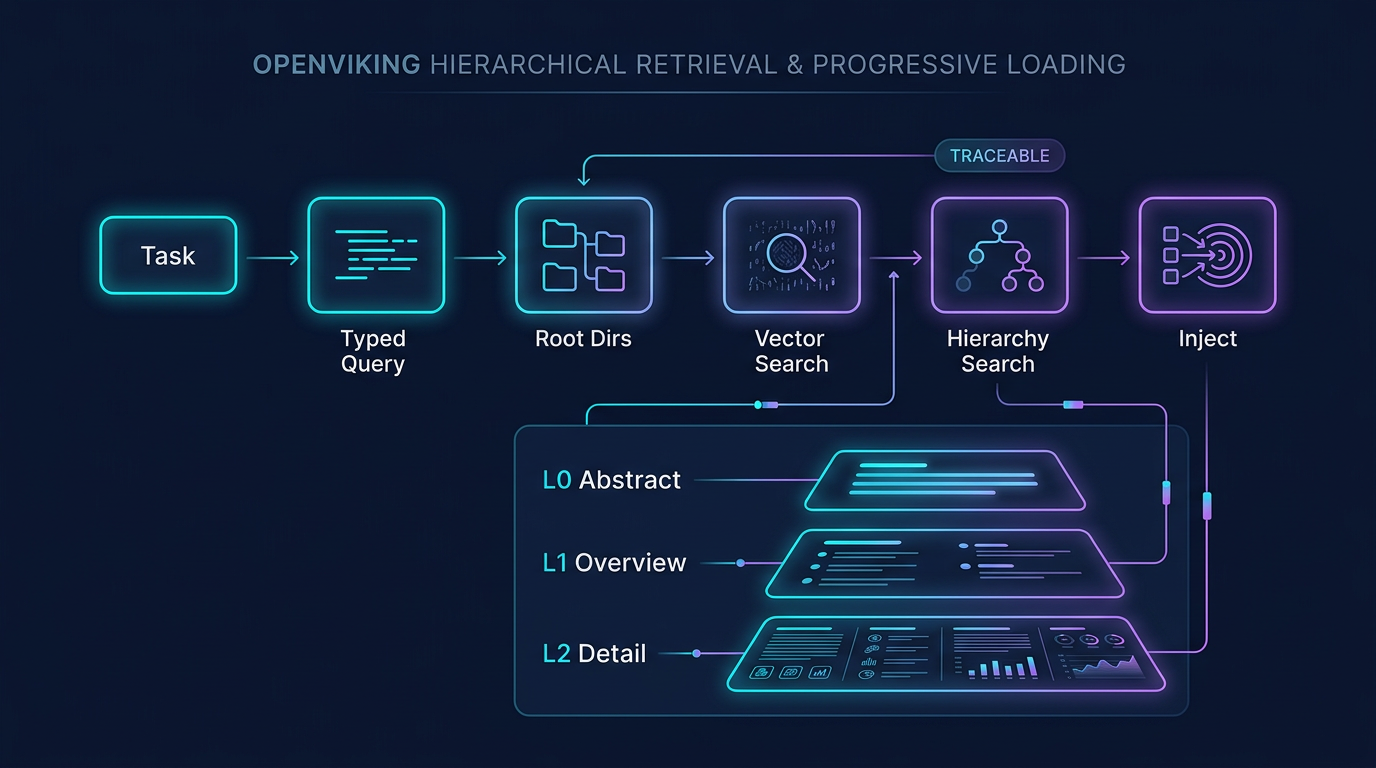
图:它避免“每轮都把大段上下文硬塞给模型”的关键,就在这套 L0 / L1 / L2 分层读取。先用便宜的摘要判断值不值得看,再看结构,最后才下钻全文,省 token 只是结果,更重要的是读取路径终于变得可控。
4)它的检索方式,为什么比普通 RAG 更像“找资料”而不是“捞碎片”?
普通 RAG 常见做法,是把内容切成很多 chunk,然后做一次 top-k 召回。它快,也够通用,但在 Agent 场景里有个老问题:你拿到的是几段相关文本,却不一定知道它们各自属于哪一层目录、跟上游任务有什么关系。
OpenViking 的路径更像人在资料库里找东西:
- 先判断这次任务更像要找 resource、memory 还是 skill
- 再确定从哪个根目录开始
- 先搜到可能相关的目录
- 再沿目录往下钻,必要时才读详细内容
这会带来一个变化:检索结果不再只是“几段像答案的文本”,而更像“我为什么会走到这里”的路径。 对长期运行的 Agent 来说,这比多召回几段 chunk 更重要。
5)为什么说它更像底座,不像插件?
判断它是不是“插件”,可以看它是在边上补一项能力,还是会反过来影响整个 Agent 的工作流。
OpenViking 属于后者。因为它一旦接进来,影响的不只是 memory 模块,而是:
- 上下文怎么建模
- 检索从哪里开始
- 信息按什么层级加载
- 任务完成后怎么 commit 和沉淀
- 出问题时怎么回放和排查
也就是说,它改的是 Agent 的“上下文供给方式”。这就不是加个挂件,更像是在换底盘。
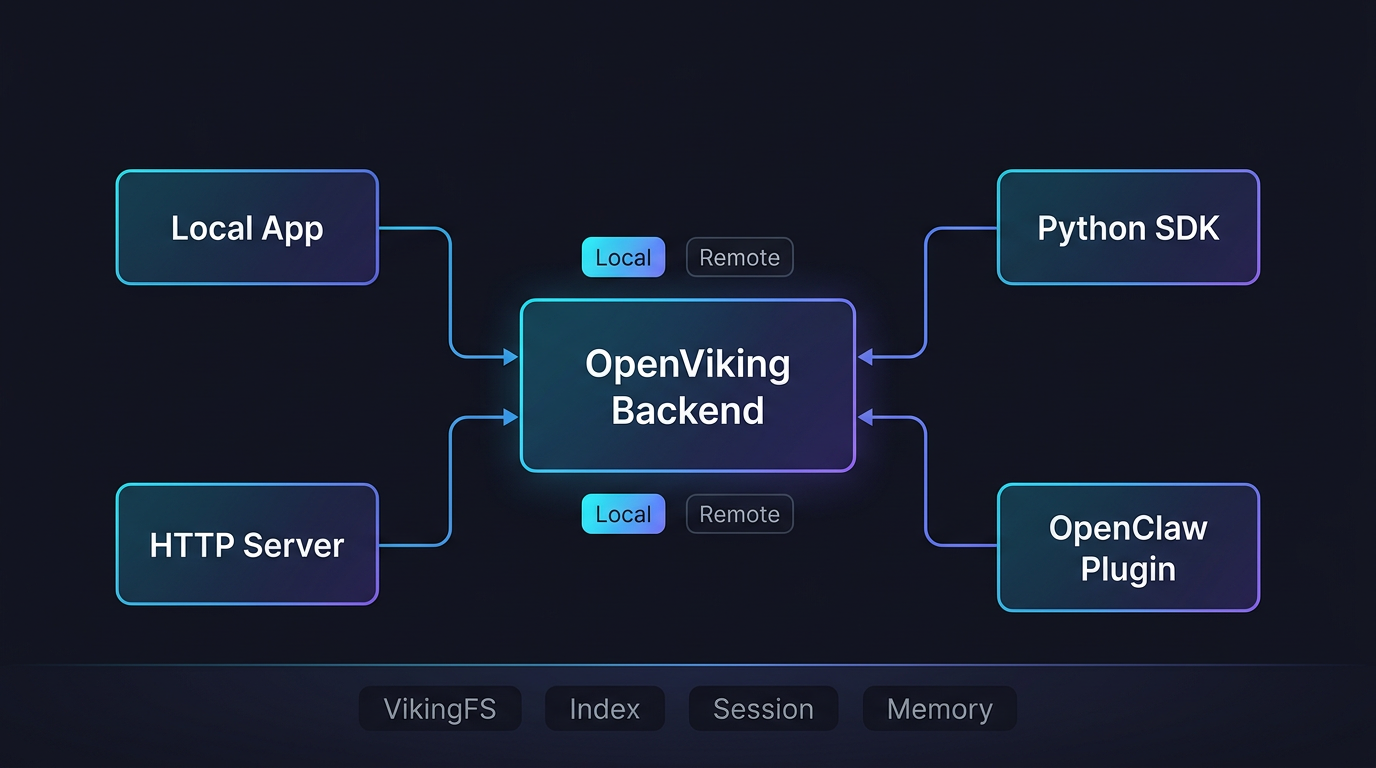
图:实际接入时,不一定要推倒重来。你可以先把它当 SDK 接进现有 Agent 流程,先接管上下文读取;如果后面多个 Agent 都要共用这套能力,再把它独立成服务。也就是说,它既能小步接入,也能往统一底座演进。
6)哪些团队会明显受益,哪些不会?
我觉得这类团队会更受益:
- 做长期运行 Agent,跨 session 记忆和资源越来越多
- 不只要“能回答”,还要知道回答是怎么来的
- 已经开始在意 token 成本、装载顺序和调试效率
- 准备把 memory / skill / resource 当成统一资产来管理
但下面这些场景,未必急着上:
- 只是聊天助手,主要记昵称、偏好、最近几轮对话
- 只是做 FAQ / 知识库问答,普通 RAG 已经够用
- 团队还在验证需求,连 Agent 是否长期运行都没确定
说白了,它更适合“上下文复杂度已经上来”的项目,不适合所有 AI 应用一上来就重装。
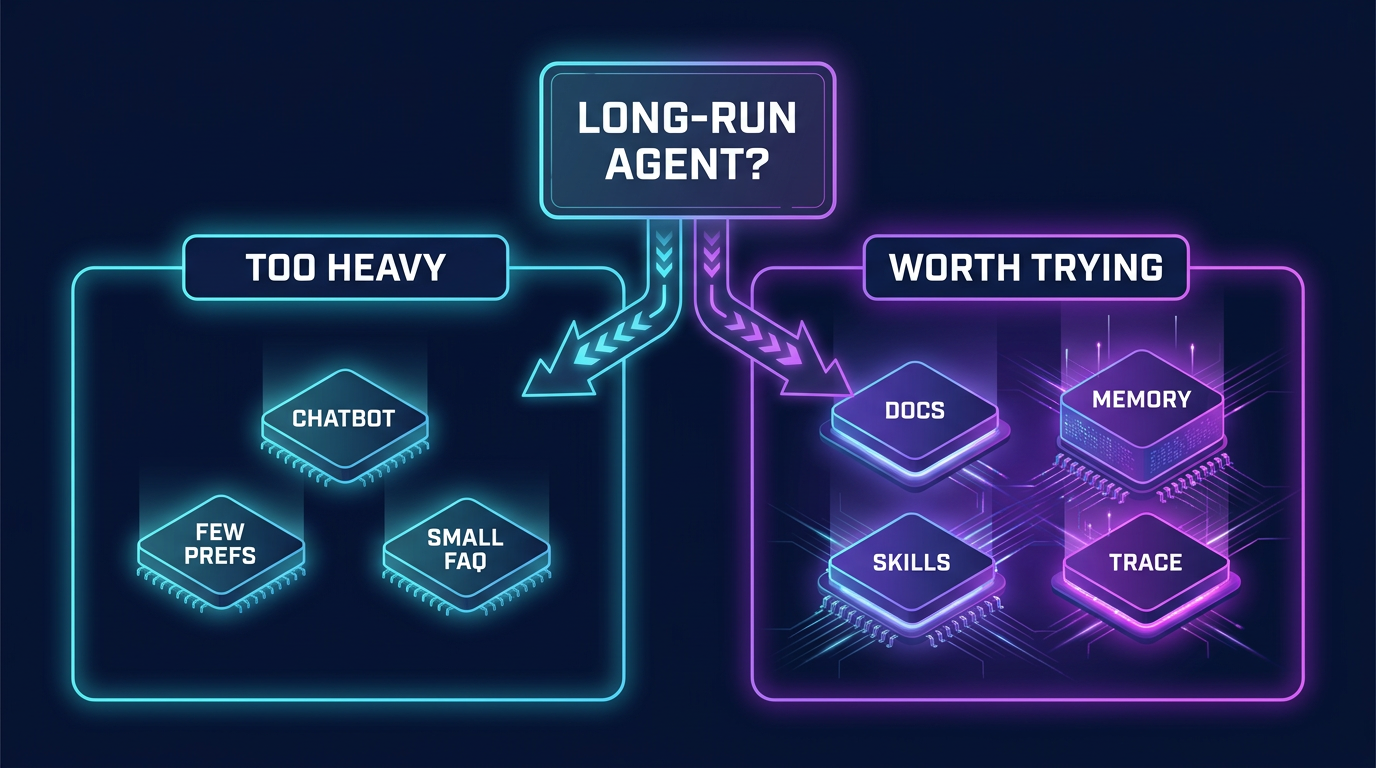
图:这张图回答的其实是“该不该现在就上”。如果你的 Agent 已经跨 session、上下文越来越杂,还要追溯决策过程,那它很值;如果只是轻量聊天或普通知识库问答,先用 memory / RAG 往往更省事。
最后一句
OpenViking 值得看的地方,不是它又给 Agent 加了一层 memory,而是它试图把 上下文本身 做成一套统一的数据结构、检索路径和加载策略。
这件事比“多记一点”更底层,也更难。但如果 Agent 真的要走向长任务、长期运行和可调试,这一层迟早都得补。
如果这篇对你有用,建议点个关注。我会持续把 GitHub 上值得用的 AI 工具拆成「最短上手闭环 + 坑点清单 + 可复用配置」,让你少走弯路。
关注微信公众号
想第一时间看到后续的工具拆解与实战更新,欢迎扫码关注公众号。
