微软把 1-bit LLM 真做出来了,BitNet 可能会改写本地推理这条线
- 对比与选型
- 2026-03-13
- 152热度
- 0评论
项目拆解
微软把 1-bit LLM 真做出来了,BitNet 可能会改写本地推理这条线
这是一篇面向技术读者的项目拆解稿:优先讲清它为什么值得看、底层机制是什么、最短能学到什么,而不是只给你一堆热闹功能点。
项目卡片
- 项目名:BitNet
- GitHub:https://github.com/microsoft/BitNet
- 涨星速度:近 24 小时新增 1400+ Star,当前总 Star 3.2 万+
- 一句话判断:这不是又一个量化 demo,而是微软在把 1-bit LLM 往一条真正可用的推理路径上推。

如果你最近在看本地推理,这个项目值得看的地方,不是参数表上又多低了几 bit。
真正值得盯的是:微软不是在做一个“把现成模型再压一压”的 demo,而是在把 1-bit LLM 往“能实际跑、能继续优化、能服务本地推理”的方向推进。
这件事为什么重要?因为一旦这条路走通,受影响的就不只是实验室里的 benchmark,而是 普通 CPU、本地设备、成本敏感场景 里那批原本跑不动、或者跑起来太贵的大模型。
和常见的 4-bit / 8-bit 量化相比,BitNet 更像是在提前押注下一代本地推理栈:不是只想省一点显存,而是想把“大模型能不能更自然地跑在 CPU 上”这件事往前推。
BitNet 到底在解决什么
我看完 README、CPU 优化说明、GPU kernel 文档和代码入口后的结论是: BitNet 想解决的是极低比特 LLM 在真实机器上怎么高效、稳定、别失真地跑。
这里的关键词有三个。
第一,极低比特。 它主打的是 BitNet b1.58,也就是常说的 ternary 权重路线。仓库里反复出现的不是常见的 INT4、INT8,而是 I2_S、TL1、TL2 这些专门给 BitNet 模型准备的格式和 kernel。
第二,不只讲论文指标,要讲可跑。 README 直接给出结论:CPU 首版在 ARM 上有 1.37x 到 5.07x 加速,x86 上有 2.37x 到 6.17x,加上 55% 到 82% 的能耗下降。后续 2026 年 1 月的新优化,又在原有基础上额外提了 1.15x 到 2.1x。
第三,不靠通用推理框架硬套。 它是基于 llama.cpp 做出来的,但 src/ggml-bitnet-mad.cpp、src/ggml-bitnet-lut.cpp、include/gemm-config.h、utils/codegen_tl1.py / codegen_tl2.py 这些文件都说明了一件事:微软不是拿现成框架直接跑,而是在改计算图、改 GEMM/GEMV、改权重布局、改代码生成。
所以如果只用一句话概括,BitNet 在做的是: 给 1-bit LLM 补齐“从模型到 kernel 到落地运行”的整条推理链。
它和常见低比特/量化推理路线,到底差在哪
这个问题必须拆开说,不然很容易误会成“又一个量化项目”。
常见路线:先有模型,再压精度
我们平时说的 4-bit、8-bit 推理,大多数是这条路:
- 先有一个 BF16 / FP16 模型
- 再做 AWQ、GPTQ、GGUF、bitsandbytes 一类量化
- 目标是尽量少掉点效果,换显存、带宽、吞吐
这条路线很成熟,也最实用。 因为你不需要重新训练一个世界,只需要把现有热门模型压到可以部署的形态。
BitNet 路线:模型本身就是按 1-bit 思路来的
BitNet 不是“把通用模型再压一次”。 它更像是:
- 模型训练阶段就接受 1.58-bit / ternary 这件事
- 推理时再给它配专门的数据布局和 kernel
- 为特定模型形状生成对应代码
仓库里的 preset_kernels/ 已经把这种思路写得很明白了。它不是谁来都能吃的通用 kernel 仓库,而是对 bitnet_b1_58-large、bitnet_b1_58-3B、Llama3-8B-1.58-100B-tokens、官方 2B 模型这些布局做适配。
换句话说,常见量化路线是“把现成模型压小”,BitNet 路线是“围绕低比特模型重做推理系统”。
这也是它最值得看、同时最不适合被吹成“所有人今天就该迁移”的地方。
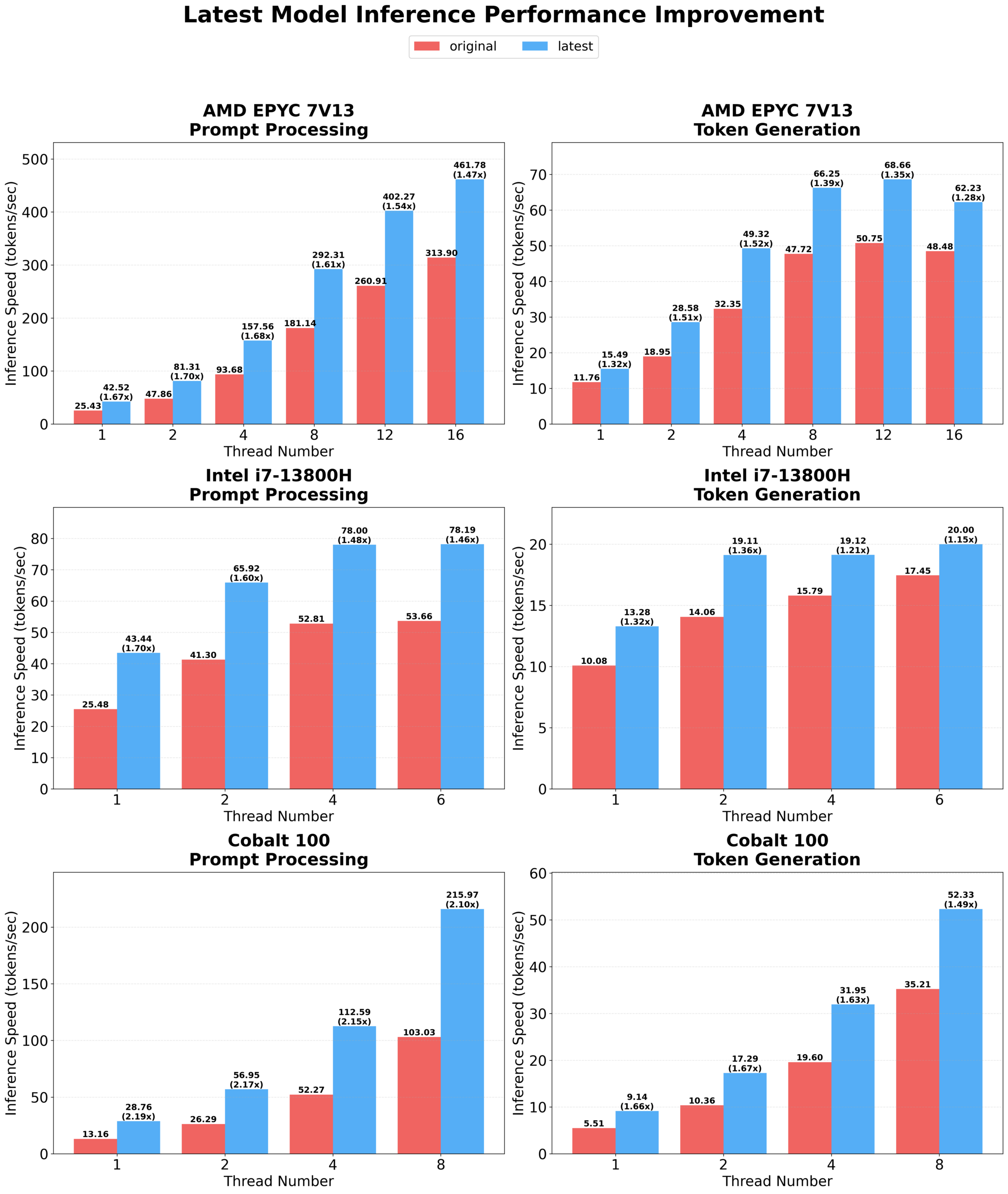
仓库 README 给出的官方总览图:核心卖点不是只有模型变小,而是 CPU 侧速度和能耗一起改善。
现在适合谁看,谁其实不用急着用
适合现在就看的人
第一类,是做本地推理、端侧推理、CPU inference 的人。 如果你关心的是“没有大 GPU 时,模型还能不能跑得像回事”,BitNet 这条线很有参考价值。
第二类,是做推理引擎、编译、kernel 优化的人。 这个仓库的价值不只在结果,也在实现思路。比如它把 I2_S 的 GEMM/GEMV 直接接进 ggml,把 activation parallel 和 weight parallel 拆开讨论,还开放了 ROW_BLOCK_SIZE、COL_BLOCK_SIZE、PARALLEL_SIZE 这些可调参数。
第三类,是在观察 1-bit LLM 生态会不会成形的人。 现在外面很多人谈低比特,还停留在“4-bit 够不够用”。BitNet 真正往前走了一步:如果训练和推理都为极低比特重构,边缘设备和 CPU-only 场景会不会被重新定义?这个问题它至少给了一个工程化答案。
不用急着上的人
如果你今天的工作重点是:
- 用现成开源模型快速上线业务
- 主要跑在 NVIDIA GPU 上
- 已经有成熟的 4-bit / 8-bit 推理方案
那你不用急着切到 BitNet。
原因很简单: BitNet 现在更像一条值得认真研究的新路线,不像一把拿来就能平替主流栈的通用锤子。
它已经能跑,也有官方模型和 CPU/GPU 路线,但生态宽度、模型通用性、部署习惯、现成工具链,都还没有主流量化路线那么顺手。
最短上手闭环:照着 README 先跑通一次
如果你只是想最快知道“它到底是不是能用”,官方给的最短闭环其实很直接。
环境要求
仓库写得比较明确:
- Python >= 3.9
- CMake >= 3.22
- Clang >= 18
- 推荐用 conda
- CPU 首发优先,x86_64 对应
i2_s/tl2,arm64 对应i2_s/tl1
Windows 还要求 VS2022 的开发环境。Linux 用户如果 clang 不够新,README 直接给了 LLVM 安装脚本。
最短命令
你会经历什么
setup_env.py 并不只是“准备环境”。 它会做几件关键事:
- 安装 gguf 相关依赖
- 按架构选择支持的量化类型
- 调用
codegen_tl1.py/codegen_tl2.py生成 kernel 代码 - 用 clang/cmake 编译整个工程
- 处理模型格式,必要时把模型转成 GGUF 或继续量化
也就是说,你第一次跑 BitNet,实质上是在走一条“生成内核 + 编译 + 准备模型”的路线,不是 pip install 完就结束。
预期结果
跑通后,本质上还是一个基于 llama-cli 的本地推理入口。 run_inference.py 最后调用的是 build/bin/llama-cli,只是前面那层准备工作和底层 kernel 都换成了 BitNet 版本。
这点很重要。 它说明 BitNet 不是另起炉灶到完全陌生,而是在熟悉的 llama.cpp 生态上,硬插进一套专门给 1-bit 模型服务的实现。
真正的门槛,不在“会不会跑命令”
很多项目的门槛在安装。 BitNet 不是。 它真正的门槛在下面这几件事。
1. 你得接受它不是通用量化万金油
include/ggml-bitnet.h 里写得很直白: 当前主要支持 BitNet quantization 或 GPTQ-like quantization;如果你拿 i-quantization 的 gguf 模型直接喂进去,结果会错。
这句话的潜台词是: 别把它当成“任何 GGUF 都能顺手提速”的通用推理壳。
2. 它对模型形状和 kernel 适配很挑
docs/codegen.md 说明了 TL1 / TL2 都要按模型矩阵形状、BM、BK、bm 去切块,而且 TL2 还有额外约束,比如 BK % 6 == 0、bm 只能选 32。
这就意味着,BitNet 的性能不是凭空来的。 它是靠更强的定制化换来的。 好处是极致,代价是没那么通吃。
3. GPU 路线能用,但语境和主流 CUDA 推理还不一样
gpu/README.md 现在给的是 W2A8 GEMV kernel,围绕的是 BitNet-b1.58-2B-4T 这条线,强调 16×32 block 权重布局、2-bit 权重打包、dp4a 指令加速。
所以如果你预期的是“直接拿它替代 vLLM 跑所有主流模型”,那会失望。 如果你看的是“极低比特模型在 GPU 上能不能也有专门 kernel”,那它是有料的。
4. 生态还在长,不是闭眼上生产
仓库已经很热,但从工程直觉看,它更适合:
- 做研究验证
- 做端侧 / CPU-only 方向预研
- 做推理内核学习
- 做下一代低比特路线的技术储备
如果你今天只想稳定上线一个业务模型,主流 4-bit / 8-bit 路线依然更省心。
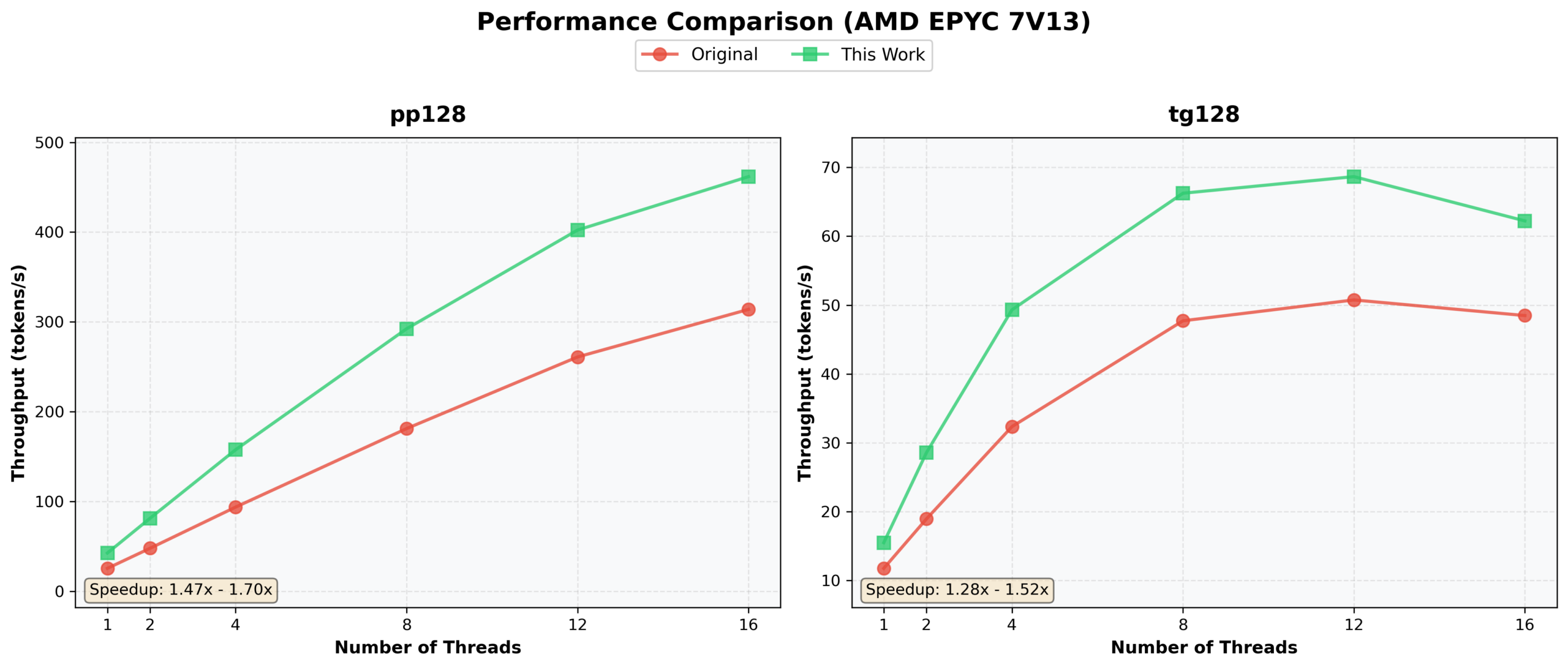
2026 年 1 月新优化给出的 AMD EPYC 对比图:这一轮不是“论文刷新”,而是在继续抠 CPU kernel 的真实吞吐。
我对 BitNet 的一句判断
如果只把 BitNet 理解成“更低比特的量化项目”,会低估它。
更准确的说法是: 它在证明一件事——极低比特 LLM 不一定只能停在论文里,只要你愿意把模型、格式、kernel、代码生成和硬件适配一起重做。
这也是为什么它现在值得看。 不是因为你明天就该把所有推理栈换掉,而是因为它把一条以前很像研究题的路线,往工程题推进了不少。
对普通开发者来说,最现实的用法不是立刻迁移生产,而是先回答两个问题:
- 你的场景到底是缺显存,还是缺功耗/带宽/CPU 可跑性?
- 你需要的是通用性,还是愿意为特定模型换更激进的效率?
BitNet 未必是所有人现在都该马上上手的项目,但它很可能会影响后面一批本地推理方案怎么做。
如果你关心的是 CPU 推理、本地部署和更低成本的大模型可用性,那它值得你花半天认真看一遍。
关注微信公众号
想第一时间看到后续的工具拆解与实战更新,欢迎扫码关注公众号。
