这个开源项目,把 Claude Code 的底层原理拆开给你看了
- Prompt / Skills / 配置
- 2026-03-09
- 31热度
- 0评论
项目拆解
这个开源项目,把 Claude Code 的底层原理拆开给你看了
这是一篇面向技术读者的项目拆解稿:优先讲清它为什么值得看、底层机制是什么、最短能学到什么,而不是只给你一堆热闹功能点。
这个开源项目,把 Claude Code 的底层原理拆开给你看了
如果你最近在用 Claude Code,或者在看各种 coding agent,一个很容易冒出来的问题是:
它到底是怎么工作的?
很多文章会告诉你它很强,会读 repo、会改代码、会跑测试、会开子任务、会并行、会长期推进。但问题是,这种介绍看完之后,你还是很难回答一个更本质的问题:
Claude Code 到底靠什么机制,才从“一个会调用工具的模型”,变成“一个真能干活的 coding agent”?
我今天想写的这个项目,刚好就把这件事拆开了。
它叫 learn-claude-code。名字很直白:不是做一个更强的 Claude Code 替代品,而是从 0 到 1,把一个 nano Claude Code-like agent 一步步搭出来。
这个项目最有意思的地方,不是它做了多少炫技功能,而是它的讲法很克制:
- 先讲最小循环
- 再讲工具调用
- 再讲 TodoWrite
- 再讲子智能体
- 再讲上下文压缩
- 再讲任务系统、后台任务、团队协作、worktree 隔离
也就是说,它不是直接扔给你一个“大而全代理框架”,而是把 Claude Code 这类 agent 的核心机制,一层一层拆给你看。
如果你真的想搞明白“coding agent 为什么能跑起来”,这个 repo 的价值比很多纯演示项目大得多。
它最值得看的地方,不是功能,而是拆解顺序
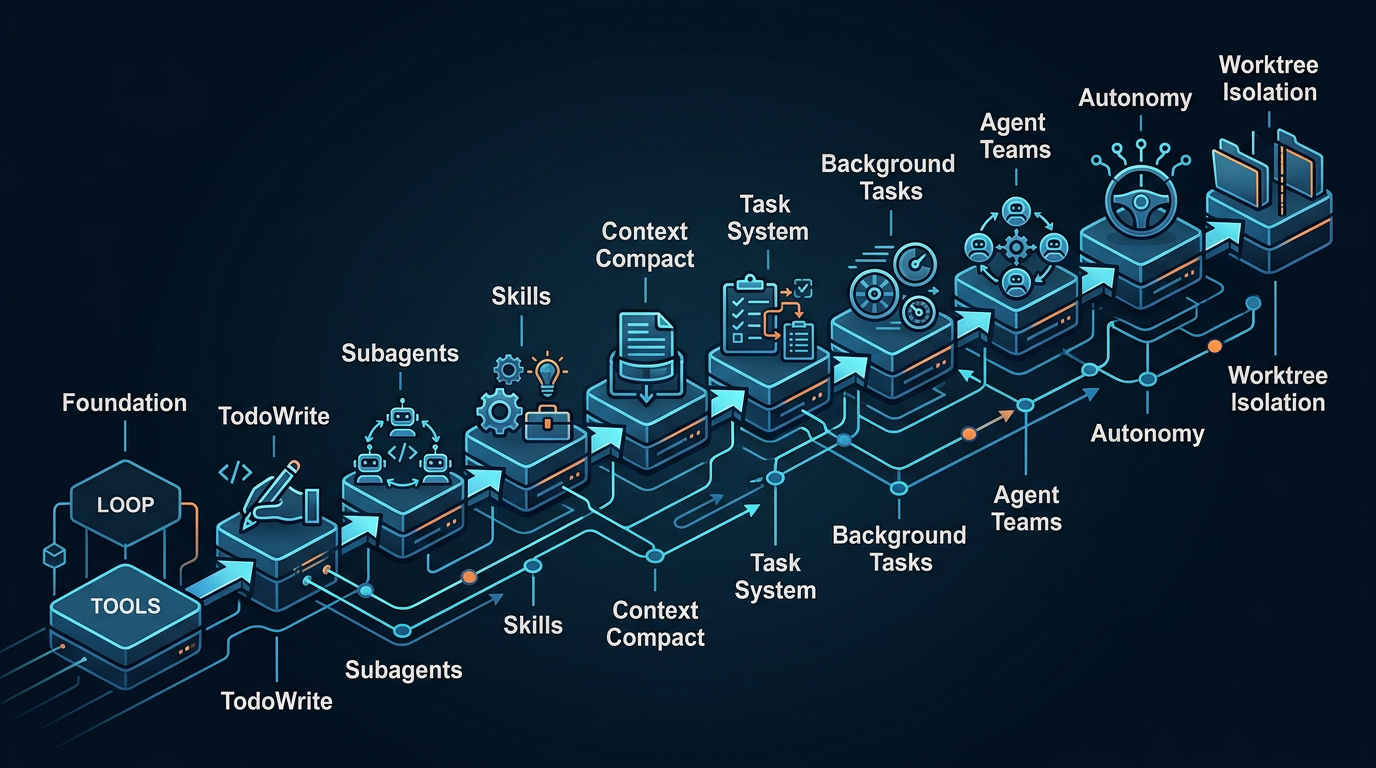
图 2:这个 repo 最有价值的不是某一个单点功能,而是它把 Claude Code-like agent 的能力递进顺序讲清楚了。
这个 repo 在 README 里给了一个很漂亮的学习路径:
- s01:最小 agent loop
- s02:tool use
- s03:TodoWrite
- s04:subagents
- s05:skills
- s06:context compact
- s07:task system
- s08:background tasks
- s09-s11:agent teams / protocol / autonomous agents
- s12:worktree isolation
这条路径本身就已经很有价值。
因为很多人今天看 agent,会天然被花哨能力吸走注意力:多智能体、自动并行、长期自治、自己认领任务、自己继续跑……但真正把这些能力撑起来的,往往不是“又一个大 prompt”,而是一些很朴素的底层机制。
这个项目做得最对的一点,就是它没有一上来就端出一整套“神秘代理系统”,而是告诉你:
先别急着谈自治。先把最小循环讲明白。
这其实很像在学编译器、操作系统或者数据库时,先把最小原理讲清楚,再谈高级特性。
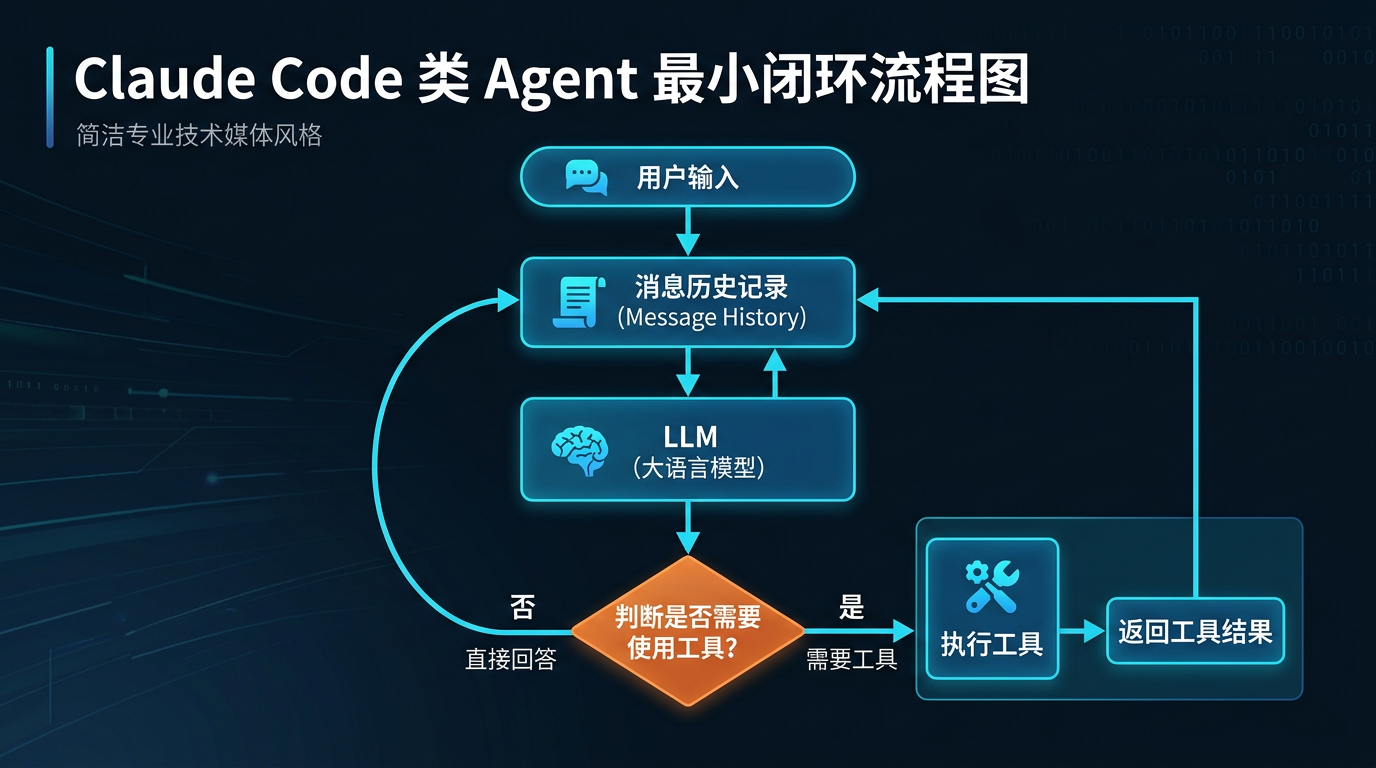
图 1:Claude Code-like agent 的最小闭环,不神秘,就是“模型 -> 工具 -> tool_result -> 再回到模型”。
Claude Code-like agent 的底层,真没那么玄
这个项目在 README 里直接给了最核心的一段伪代码,大意是这样的:
如果你以前总觉得 Claude Code 这类产品像黑盒,看完这段其实会突然松一口气:
它最底层的秘密没那么神,就是一个 while 循环。
这个循环干的事很简单:
- 把当前上下文发给模型
- 看模型是不是要调用工具
- 如果要,就执行工具
- 把工具结果再塞回上下文
- 继续下一轮
- 直到模型决定停止
从“聊天”到“代理”,本质上就多了这条循环。
很多人误以为 coding agent 的突破在“模型突然变聪明了”,但这个项目在提醒你一件更重要的事:
模型能力当然重要,但真正让它动起来的是循环、工具和状态回流。
这也是为什么这个 repo 的第一课就叫:
One loop & Bash is all you need
这句话看着像口号,其实是很实在的工程判断。
第一层能力:不是先写代码,而是先学会调用工具
项目的 s01 和 s02 很适合拿来纠正一个误区:
很多人以为 agent 的起点是“会改文件”。其实不是。 真正的起点是:
模型得先学会把自然语言意图变成结构化工具调用。
在这个项目里,最早的工具就是 bash。没有复杂抽象,没有花哨框架,就是让模型先学会:
- 什么时候该动手
- 动什么手
- 工具执行完之后怎么继续
这一步为什么重要?
因为没有它,模型永远只是“会建议你下一步做什么”;有了它,模型才开始变成“自己去做下一步”。
这中间的差距,比很多人想象得大。
第二层能力:TodoWrite 不是装饰,是防漂移的关键
我觉得这个 repo 里最值得很多人认真看的一个点,是 s03 TodoWrite。
很多人把 todo list 理解成“界面层的小功能”,好像只是为了让用户看着舒服。但这个项目把它讲得很清楚:
没有计划的 agent 会漂。
它在 s03 里不是简单加了一个 todo 工具,而是加了一个结构化的 TodoManager:
- 最多 20 项
- 每项有 id、text、status
- status 只能是 pending / in_progress / completed
- 同一时间只能有一个 in_progress
- 如果 agent 连续几轮没更新 todo,还会插入 reminder 提醒它更新
这不是 UI 小修饰,这是一个非常典型的“把状态显式化”的做法。
为什么它重要?
因为 coding agent 一旦任务稍微变长,就特别容易出现两种问题:
- 走到哪算哪
- 做了很多事,但系统自己说不清现在做到哪一步
TodoWrite 的价值,不只是给人看进度,而是让 agent 自己也被迫把当前状态讲清楚。
说白了,TodoWrite 不是为了好看,而是为了防止 agent 漂。
这点我觉得很多做 agent 的人都会低估。
第三层能力:并行不是“多开几个 agent”,而是先处理后台任务
这个项目还有一个我很喜欢的设计点:它没有一上来就把“多智能体”包装成一个很神秘的能力,而是先讲 background tasks。
s08 的核心思路其实很朴素:
- 把慢命令丢到后台线程跑
- 主 agent 不要傻等
- 完成后通过通知队列把结果再塞回来
它在代码里做的是:
- 后台线程执行命令
- 结果写进 notification queue
- 每次 LLM 调用前,先 drain 这个队列
- 再把结果作为一条系统可见的新信息注入回去
这件事为什么重要?
因为很多人一说并行,就直接想到“多 agent team”。但实际工程里,更先碰到的问题往往是:
一个慢命令别把整个 agent 卡死。
你先把后台任务做对了,再谈真正的 agent team,路线才是稳的。
所以这个 repo 的价值不只是讲“多智能体”,而是它把前置台阶补全了:
- 先有 loop
- 再有 tools
- 再有 todo
- 再有 background tasks
- 再谈 teams
这条路比“直接上多 agent 框架”靠谱得多。
第四层能力:Claude Code 真正难的不是会改代码,而是会隔离复杂任务
这个 repo 到后面最有意思的一节,是 s12:worktree + task isolation。
如果你用过 Claude Code,或者看过更复杂的 coding agent,你会慢慢意识到:
系统真正难的地方,往往不是“让它改一段代码”,而是:
- 多任务并行时互不污染
- 每个任务有自己的目录和执行空间
- 主流程知道谁在干哪件事
- 失败时能回收、能清理、能复盘
s12 的做法很清楚:
- task 负责目标和状态
- worktree 负责目录和执行空间
- 两者通过 task_id 绑定
这个设计我觉得很值得单独记下来:
任务是控制面,worktree 是执行面。
这句话说透了为什么很多“看起来会干活”的 agent 一到复杂任务就容易乱:
因为它们只有目标,没有执行隔离。
而 worktree 这类机制,本质上是在给 agent 增加“多工但不打架”的能力。

图 3:如果把这个 repo 压缩成一句话,它其实是在解释 4 个关键词:循环、计划、并行、隔离。
这个 repo 最适合什么人看?
我觉得它特别适合 3 类人。
第一类:正在用 Claude Code,但还不知道它为什么能跑起来的人
你会用,不代表你理解它的底层。
这个 repo 最适合用来补那块“我知道它很强,但我说不清它为什么强”的空白。
第二类:想自己做 coding agent / agent runtime 的人
如果你不是想找一个现成产品,而是想自己做:
- 工具调用循环
- 任务系统
- 子智能体
- 长任务处理
- agent team
- worktree 隔离
那这个 repo 的价值会很高。因为它不是给你一个结论,而是给你一条递进路径。
第三类:已经看腻了“又一个 AI Agent demo”的人
现在很多 agent 项目看起来很热闹,但你仔细问它的底层:
- 状态怎么管理?
- 长任务怎么推进?
- 为什么不会漂?
- 并发怎么做?
- 任务怎么隔离?
很多项目是答不细的。
这个 repo 至少是在认真回答这些问题。
它也有明确边界,这反而是优点
README 里有一段我挺喜欢,因为它很老实。
它明确说了:这是一个 0→1 的学习型项目,不是完整复刻生产版 Claude Code。它刻意省略或简化了很多生产机制,比如:
- 完整事件 / hook 总线
- 基于规则的权限治理与信任流程
- 更完整的 session lifecycle 控制
- 完整 MCP runtime 细节
这反而让我更愿意推荐它。
因为一个教学型项目最怕两件事:
- 什么都想讲,最后什么都讲不清
- 把 demo 包装成生产级神话
learn-claude-code 反而比较克制。它不装自己是完整工业系统,而是老老实实地把核心机制拆给你看。
教学项目最可贵的,不是“大而全”,而是知道自己该省略什么。
它还有一个很妙的对照:Claude Code 是临时会话,OpenClaw 是常驻系统
这个 repo 后面还有一段很有意思,直接把 learn-claude-code 和 claw0 / OpenClaw 放在一起对照。
它的判断非常准确:
- learn-claude-code 这类 agent,更接近 use-and-discard 模式
- 开终端,给任务,做完关掉,下次再开基本是新会话
- 这很像 Claude Code 的核心使用方式
而 OpenClaw 代表的是另一条路:
- heartbeat
- cron
- IM channel routing
- persistent memory
- soul personality
也就是把 agent 从“踹一下动一下”的工具,变成“会自己醒来找活干”的常驻系统。
这一段我觉得特别值得看,因为它把两类东西分得很清楚:
Claude Code 更像强执行者,OpenClaw 更像长期运行的外层系统。
而 learn-claude-code 这个 repo,刚好处在中间:
它不是在做 always-on assistant,而是在把 Claude Code 这类 runtime 的内部结构摊开给你看。
这也是为什么我觉得它很适合写。
它不是一个简单的“替代品项目”,而是一个非常适合拿来讲清楚底层原理的教学仓库。
如果你只想知道值不值得看,我给你一个最短判断
如果你只是想找一个现成工具,拿来马上替代 Claude Code,未必是它最强的用法。
但如果你想搞清楚下面这些问题:
- coding agent 的最小循环到底是什么
- tool use 是怎么接进循环的
- TodoWrite 为什么不是装饰
- 背景任务怎么避免 agent 卡死
- 多 agent 为什么需要协议
- worktree 为什么是复杂任务的关键机制
那 learn-claude-code 很值得你认真看一遍。
它最大的价值,不是告诉你“Claude Code 很强”,而是告诉你:
Claude Code 这类系统,到底是怎么一层一层长出来的。
这比单纯看演示视频有用得多。
最后一句
如果你对 Claude Code 的兴趣已经从“会不会用”进入到“我想知道它为什么这么设计”,那这个 repo 很适合你。
因为它不是在卖一个神秘 agent,而是在把神秘感拆掉。
很多人以为 coding agent 的秘密在更强的模型,其实更关键的是:循环、工具、状态、并行和隔离。
而 learn-claude-code,正好把这五件事,拆成了一条可以跟着走的学习路径。
如果这篇对你有用,建议点个关注。我会持续把 GitHub 上值得用的 AI 工具拆成「最短上手闭环 + 坑点清单 + 可复用配置」,让你少走弯路。
关注微信公众号
想第一时间看到后续的工具拆解与实战更新,欢迎扫码关注公众号。
